Guides
3 min read
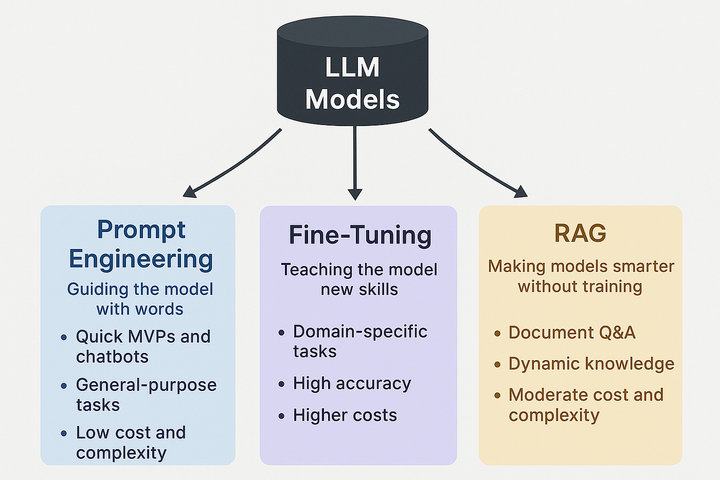
Fine-Tuning vs. RAG vs. Prompt Engineering: How to Choose
Introduction With open-weight models like Gemma 4, Qwen3, and Trinity-Large-Thinking now downloadable and fully customizable, developers face a decision that used to
Read