
What It Is
Two distinct visions of agentic AI are crystallizing in 2026. OpenAI's GPT-5.5 is a broadly available flagship engineered for autonomous multi-step computer work — debugging sprawling codebases, navigating spreadsheets, conducting web research — without granular human steering. Anthropic's Claude Mythos Preview is something structurally different: a restricted-access model that Anthropic has declined to commercialize due to classified cybersecurity risks, sharing it only with government agencies, critical-infrastructure operators, and a narrow circle of vetted partners.
For most developers, this distinction is decisive before a single benchmark is examined. GPT-5.5 is the model you can actually ship with. Mythos is a research artifact and a competitive benchmark — not a product you can integrate today.
What's changed this week is that both companies are also moving hard on real-world integrations. Anthropic quietly launched personal app connectors for Claude — Spotify, Uber Eats, TurboTax, Instacart, AllTrails — expanding an ecosystem previously focused on Microsoft productivity tools. Meanwhile OpenAI is positioning GPT-5.5 as a core layer in a future "super app" that merges ChatGPT, Codex, and an AI browser.
Key Capabilities and Benchmarks
GPT-5.5's headline agentic number is Terminal-Bench 2.0: 82.7% accuracy on sandboxed terminal task completion, edging Mythos Preview (82.0%) and comfortably clearing Claude Opus 4.7 (69.4%). On OSWorld-Verified GUI automation, GPT-5.5 scores 78.7% versus Mythos's 79.6% — essentially parity. CyberGym follows the same pattern: GPT-5.5 at 81.8%, Mythos at 83.1%.
Where the gap opens is pure reasoning under zero-shot conditions. On Humanity's Last Exam without tools, GPT-5.5 Pro scores 43.1% — meaningfully behind Mythos Preview's 56.8% and even Opus 4.7's 46.9%. For knowledge-intensive workflows that don't rely on tool calls, OpenAI's model is not the strongest option.
GPT-5.5's efficiency story is genuine. OpenAI co-designed the serving stack with NVIDIA GB200/GB300 NVL72 hardware, using AI-generated heuristics to balance GPU workloads and reportedly boosting token throughput by over 20%. The model matches GPT-5.4 latency while delivering measurably higher task completion quality — a credible improvement for agentic pipelines where latency compounds across many tool calls.
On SWE-bench Pro (public), Claude Opus 4.7 still leads at 64.3% versus GPT-5.5's 58.6%, with Mythos reaching 77.8% — confirming that for pure software engineering, Anthropic's models retain an edge among commercially available options.

How It Compares
For developers building agent pipelines today, the commercially relevant matchup is GPT-5.5 vs. Claude Opus 4.7, not GPT-5.5 vs. Mythos. On that basis, GPT-5.5 leads across 14 benchmarks vs. Opus 4.7's 4, dominating on computer-use tasks (OSWorld, GDPval, OfficeQA Pro), mathematics (FrontierMath Tier 1–4), and cybersecurity work (CyberGym). Opus 4.7 retains advantages in code generation (SWE-bench Pro) and unassisted reasoning.
Claude's new connectors change the integration calculus for consumer-facing agents. The ability to orchestrate Spotify, Uber Eats, and TurboTax natively — with Anthropic confirming no paid placements and explicit user confirmation before purchases — gives Claude a compelling story for lifestyle and personal-finance agent use cases. OpenAI has some overlap (Spotify connectors exist in ChatGPT), but the breadth of Anthropic's new consumer connector rollout is a differentiator for developers targeting non-enterprise end users.

The Mythos situation deserves a sober read. The Guardian's editorial board flagged that Mythos can autonomously discover zero-day vulnerabilities, chain exploits, and compromise major operating systems — capabilities Anthropic itself deemed too dangerous for public release. OpenAI's GPT-5.5 is classified "High" risk for cyber capabilities under its own Preparedness Framework, with API access gated behind additional safeguards still being finalized.
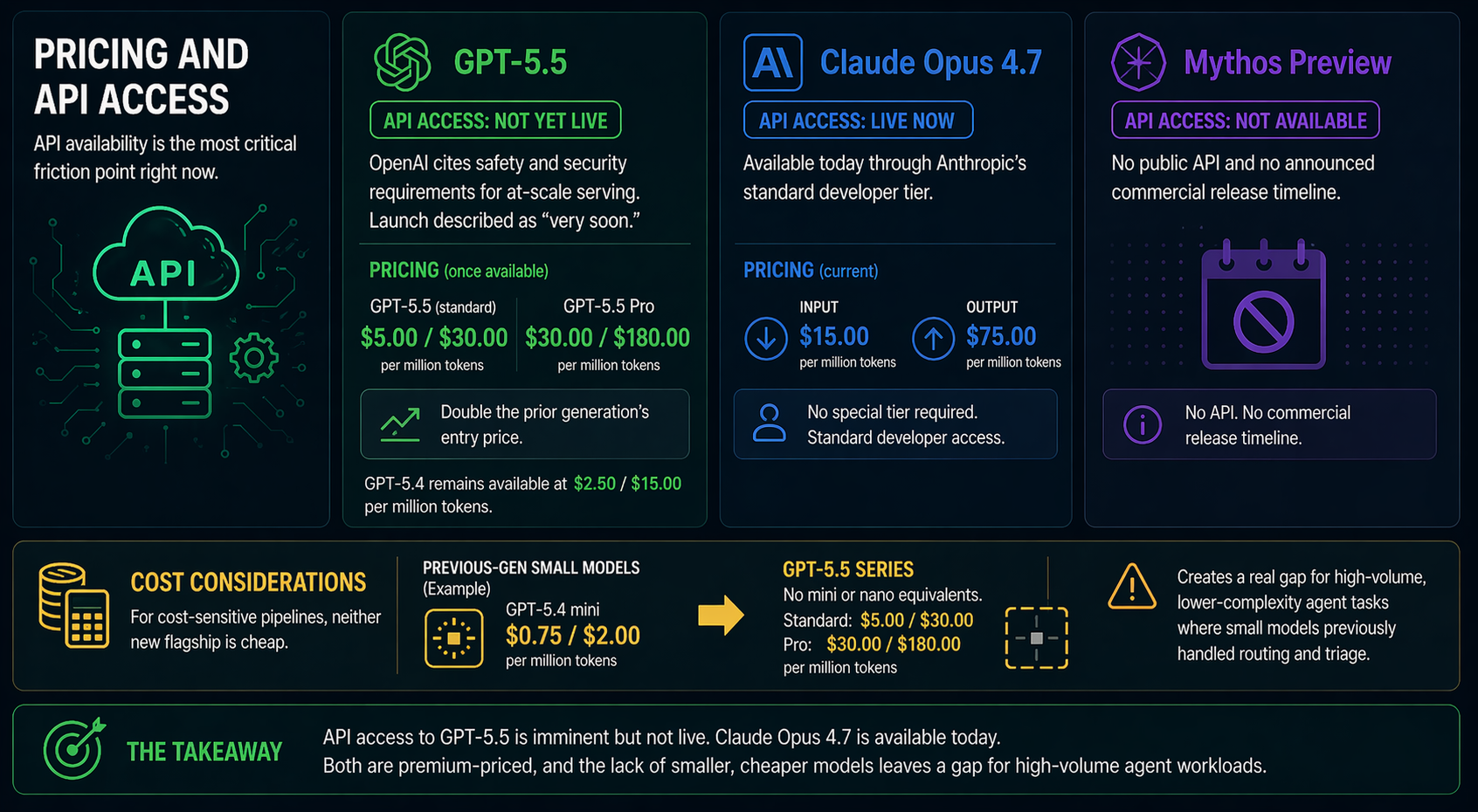
Pricing and API Access
API availability is the most critical friction point right now. GPT-5.5 API access is not yet live — OpenAI cites safety and security requirements for at-scale serving, with launch described as "very soon." Current pricing once available: $5.00 input / $30.00 output per million tokens for standard GPT-5.5, and $30.00 / $180.00 for GPT-5.5 Pro — double the prior generation's entry price. GPT-5.4 remains at $2.50 / $15.00 and stays available.
Claude Opus 4.7 API access is live today through Anthropic's standard developer tier. Mythos Preview has no public API and no announced commercial release timeline.
For cost-sensitive pipelines, neither new flagship is cheap. The absence of GPT-5.5 mini or nano equivalents (GPT-5.4 mini was $0.75/M input) creates a real gap for high-volume, lower-complexity agent tasks where previous-gen small models handled routing and triage.
Bottom Line
Build with Claude Opus 4.7 if your agent pipeline is code-heavy or requires strong unassisted reasoning, and you need API access today without waiting on OpenAI's rollout window.
Build with GPT-5.5 once the API ships if your priority is computer-use automation, agentic computer work across tools, or economic and financial knowledge tasks — Terminal-Bench, OSWorld, GDPval, and OfficeQA Pro numbers make it the stronger orchestration backbone for those use cases.
Build with Claude for consumer integrations if personal-app connectors (Spotify, Uber Eats, TurboTax) are core to your product. The connector ecosystem Anthropic just opened is a genuine differentiator for lifestyle-agent use cases that GPT-5.5 hasn't matched at launch breadth.
Mythos Preview is not a real option for commercial development and should be treated purely as a competitive benchmark signal — one that shows Anthropic has more headroom above Opus 4.7 than OpenAI has currently closed with GPT-5.5.
