
The gap between frontier capability and frontier cost just became a strategic decision you can no longer defer. OpenAI's GPT-5.5 landed at $5/M input and $30/M output tokens — exactly double GPT-5.4 costs at $2.50 and $15. Simultaneously, DeepSeek shipped V4-Pro and V4-Flash under MIT license, with V4-Pro priced at $1.74/$3.48 and V4-Flash at $0.14/$0.28. For developers architecting multi-step agentic systems, this isn't an abstract benchmark debate. Token costs compound across every reasoning hop.
Why This Matters for Agent Developers
Agentic pipelines don't make one API call — they make dozens. A CrewAI workflow with a planner, executor, and critic agent can easily burn 50–200K tokens per user task. At GPT-5.5 output pricing, that's $1.50–$6.00 per run. At V4-Flash output pricing, it's $0.014–$0.056. That's a 100x cost delta before you've served a single production user at scale.
The InfoWorld analysis of the current agentic frenzy flagged this directly: token consumption in multi-step workflows is already triggering capacity constraints and price increases across vendors. Planning for cost per workflow — not cost per token — is the correct unit of analysis.
How It Works
GPT-5.5's agentic edge is real. On Terminal-Bench 2.0, it scores 82.7% versus Claude Opus 4.7's 69.4%. On FrontierMath Tier 4 it hits 35.4% against DeepSeek V4-Pro's publicly unverified scores. It also matches GPT-5.4 per-token latency while using fewer tokens per Codex task — a genuine efficiency gain, though one you're still paying frontier prices for.
DeepSeek V4-Pro takes a fundamentally different approach: a hybrid attention architecture that cuts FLOPs to 27% and KV cache to 10% of V3.2 at one-million-token context. V4-Flash pushes even lower — 10% FLOPs, 7% KV cache. This structural efficiency, not subsidized pricing, explains how they undercut the market. The tradeoff: DeepSeek acknowledges V4-Pro trails frontier models by roughly three to six months. For more detail, see the technical report.
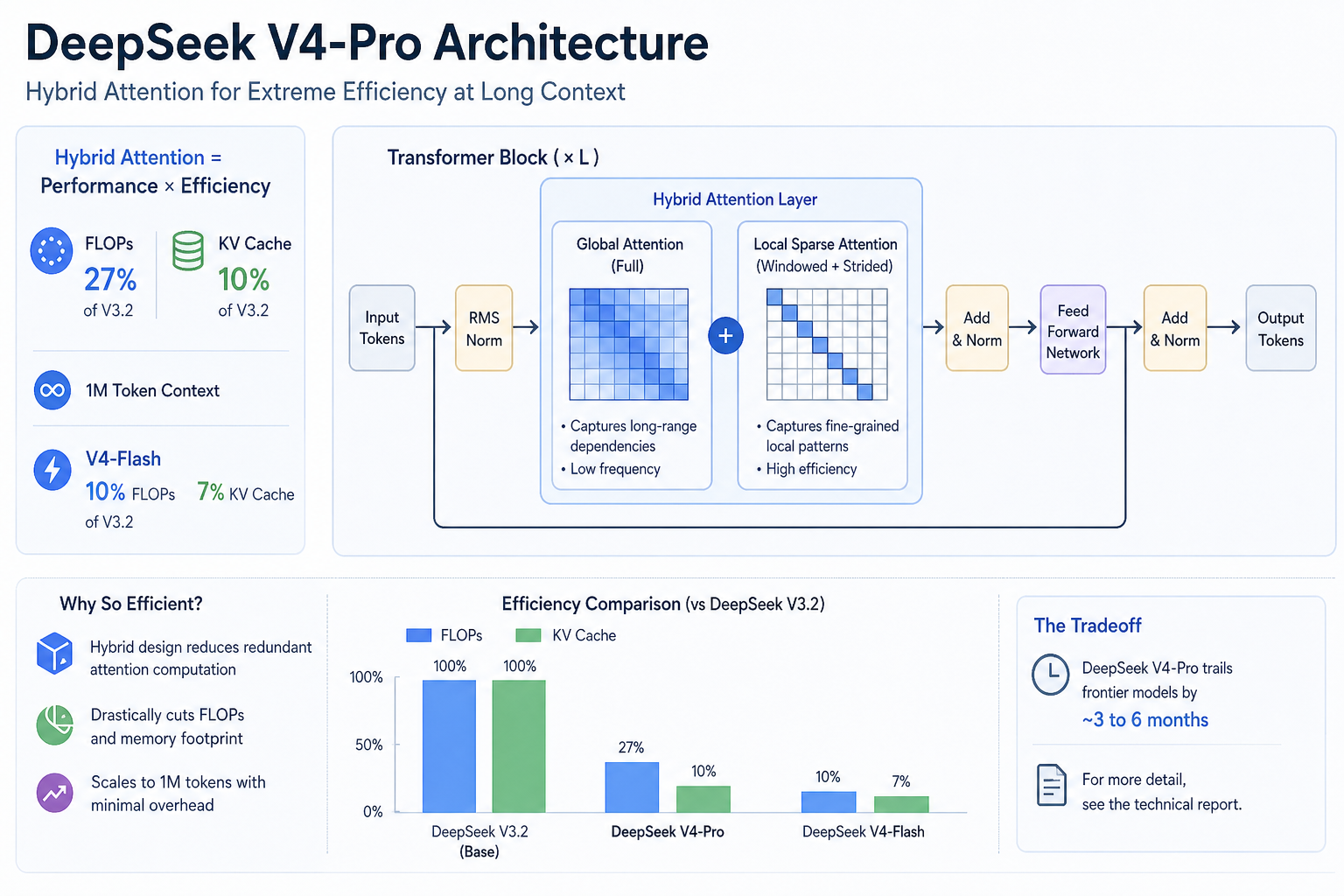
Setup and Integration
Both models expose OpenAI-compatible APIs, which means your existing LangChain or AutoGen code requires minimal changes. For DeepSeek, swap the base URL and key:
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model="deepseek-v4-pro",
base_url="https://api.deepseek.com/v1",
api_key=DEEPSEEK_API_KEY,
)
DeepSeek also ships an Anthropic-compatible interface, covering Claude-based CrewAI setups. GPT-5.5 API access is listed as "coming very soon" — currently it's ChatGPT Plus/Pro/Enterprise only — so AutoGen pipelines targeting it should maintain GPT-5.4 fallback routing for now.
- For self-hosted use, DeepSeek V4-Pro is available on Hugging Face under MIT license. Running 1.6T parameters with 49B active MoE requires serious infrastructure, but V4-Flash at 284B total / 13B active is more tractable on multi-GPU setups with the open-source MegaMoE kernel.
Real-World Use Cases
The practical layering strategy that makes sense right now:
- Planning / orchestration layer: GPT-5.5 or V4-Pro. This is where ambiguous goal decomposition matters most. GPT-5.5's 82.7% Terminal-Bench score and ability to handle messy multi-part tasks autonomously justify the cost if your workflow runs infrequently or serves enterprise clients.
- Execution / tool-calling layer: V4-Flash. Cheap, fast, one-million-token context, and already integrated with Claude Code and OpenCode internally at DeepSeek. Validated for agentic coding workflows.
- Critic / eval loops: V4-Flash again. Running a self-critique pass at $0.28/M output tokens is viable at scale; doing it with GPT-5.5 at $30/M is not.
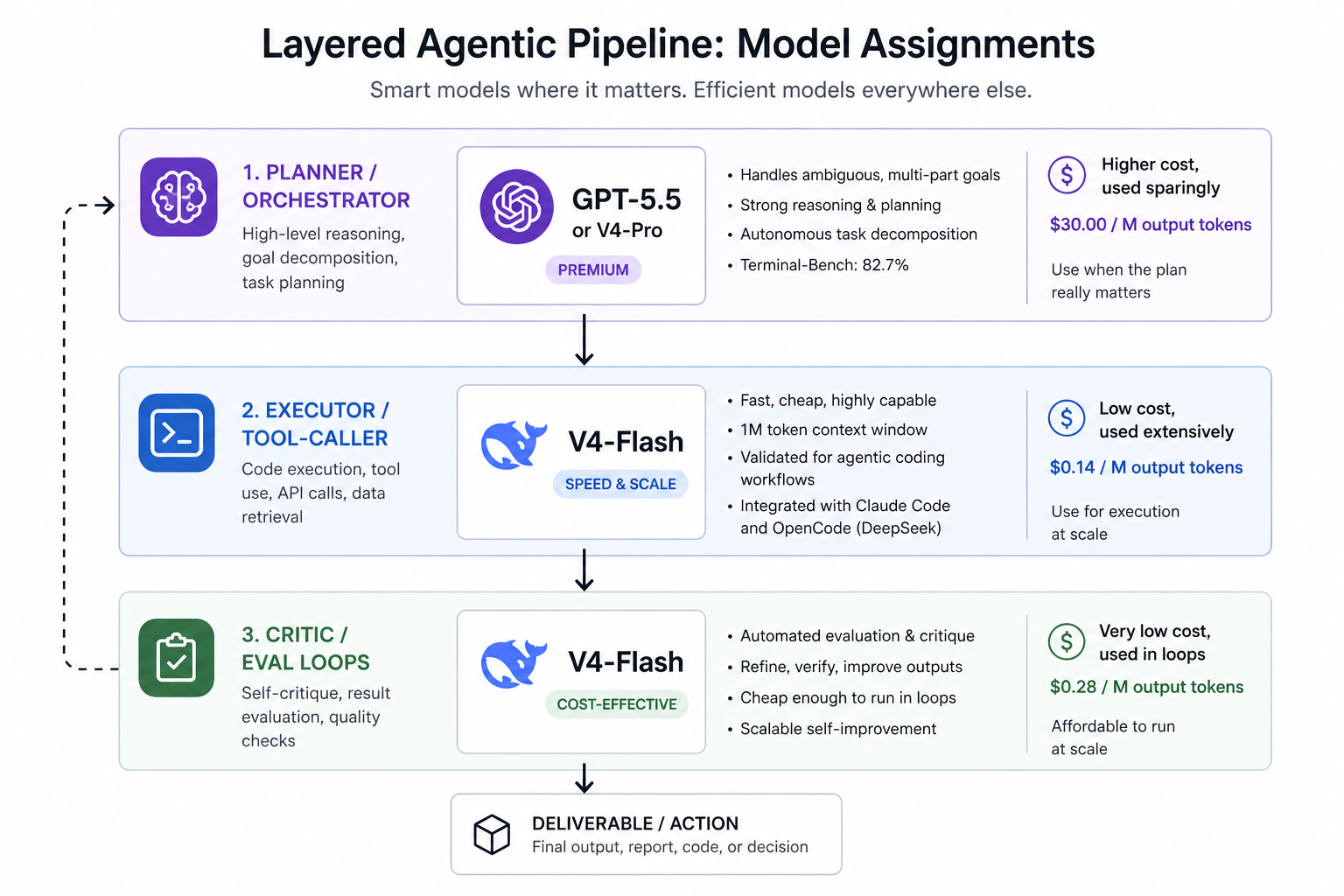
Limitations and Gotchas
GPT-5.5's weaknesses are worth knowing: it trails Claude Opus 4.7 on SWE-Bench Pro (58.6% vs 64.3%), and scores below Gemini 3.1 Pro on MCP Atlas tool-use and BrowseComp. If your agent stack depends heavily on real GitHub issue resolution or structured tool selection, GPT-5.5 isn't the unambiguous winner.
DeepSeek's risks are different in character. The V4 training corpus lacks transparent dataset sourcing. Export control exposure is real for regulated industries — running open weights on Huawei Ascend hardware in a supply-chain context requires legal review. Distillation from in-house specialist models rather than GPT/Claude mitigates IP concerns somewhat, but the paper is deliberately vague. Benchmark coverage from third parties is still incomplete; Artificial Analysis testing was ongoing at release.
Vendor lock-in calculus also differs. As one analyst framed it in the InfoWorld coverage: adding an intelligence layer to your workflows is like building neuronal pathways — a "brain transplant" later is genuinely costly. DeepSeek's MIT license and OpenAI-compatible interface hedge this more than a GPT-5.5-only bet would.
What This Means for Your Stack
The honest answer: you probably need both. GPT-5.5 wins on raw agentic computer-use performance and long-context reliability — if API access materializes quickly and you can justify $30/M output for high-value orchestration tasks, it earns its place at the top of the stack. But routing every token through it is financially indefensible at scale.
DeepSeek V4's architecture makes it the strongest case yet for a tiered inference strategy in production. Use V4-Flash for high-frequency execution hops, V4-Pro as your cost-efficient planner, and reserve GPT-5.5 for tasks where its Terminal-Bench lead actually maps to your domain. Monitor GDPval — the 44-occupation real-world task benchmark where GPT-5.5 barely moved versus GPT-5.4 — as a leading indicator that frontier pricing doesn't always buy frontier real-world gains.
