
Two converging realities should have every agent developer rethinking their threat model this week. First, AI systems are now capable of turning patches into working exploits in under 30 minutes. Second, Mozilla's agentic pipeline — running Claude Mythos Preview — independently discovered 271 previously unknown Firefox vulnerabilities, some buried in codebases for two decades. The same capability that makes agents powerful for defense makes them lethal as offensive tools. If your pipeline isn't hardened, you're building on sand.
Why This Matters for Agent Developers
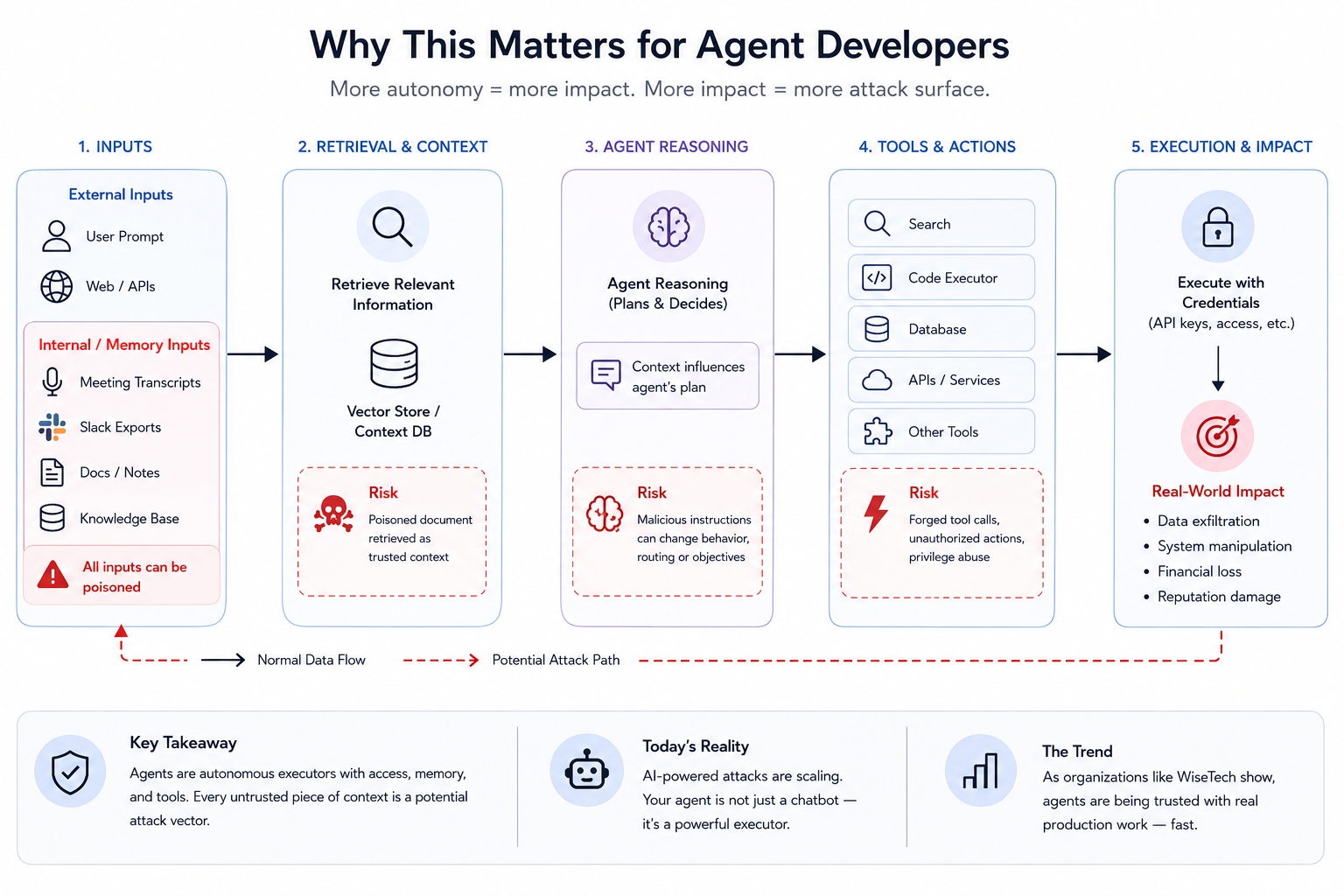
The attack surface for agentic systems is fundamentally different from traditional web apps. Agents don't just process inputs — they reason over them, route them to tools, and execute side effects. A single poisoned document in a retrieval pipeline can instruct your agent to exfiltrate data, forge tool calls, or silently rewrite its own system prompt. Google's threat intelligence teams have confirmed AI-powered hacking has crossed into industrial-scale territory. Your agent isn't just a chatbot with plugins anymore; it's an autonomous executor with credentials, API keys, and write access.
The WiseTech restructuring — where thousands of engineers are being replaced by agents that reportedly learn a job in fifteen minutes — illustrates how fast autonomous execution is being trusted with real production responsibility. More autonomy equals more exploitable attack surface.
How It Works
The three dominant attack vectors against agentic pipelines are prompt injection, tool call manipulation, and context poisoning.
Prompt injection occurs when malicious instructions embedded in external content — web pages, PDFs, emails, Slack messages — override your system prompt. Mozilla's pipeline demonstrates why this is urgent: agents that can write and execute their own test cases are also agents that can be instructed to write and execute adversarial test cases if their input isn't sanitized.
Tool call manipulation targets the gap between what your LLM intends to call and what actually executes. In frameworks like LangChain or AutoGen, tools are invoked based on LLM output. If an attacker can shape that output — via injection or jailbreak — they control your tool execution graph.
Context poisoning is subtler. As SageOX's agentic context infrastructure work reveals, agents are now being primed with shared organizational memory: meeting transcripts, Slack threads, architecture decisions. If that memory layer is writable by untrusted parties, attackers can plant false context that drifts agent behavior over time — silently, across sessions.

Setup and Integration
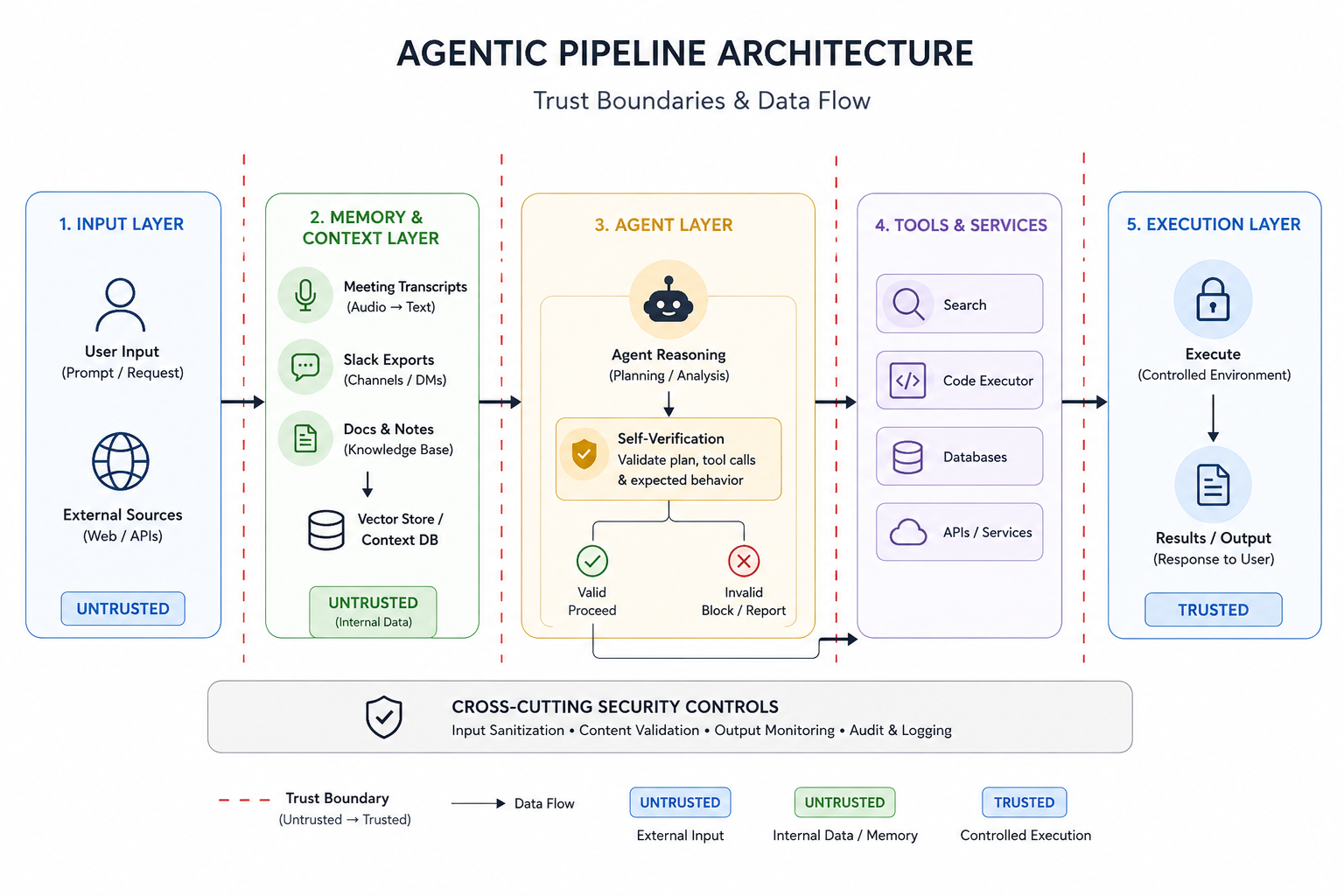
Start with a defense-in-depth approach at three layers:
Input sanitization before the LLM sees it. Strip or fence external content. In LangChain, wrap retrieval tool outputs with a sanitization step before they enter the prompt:
def sanitize_retrieved_content(raw: str) -> str:
# Remove instruction-like patterns from external docs
import re
return re.sub(r'(?i)(ignore previous|new instruction|system:)', '[REDACTED]', raw)
This is crude but catches obvious injection attempts. Pair it with an LLM-based classifier that scores content for adversarial intent before it enters context.
Tool call allow-listing. In AutoGen and CrewAI, never expose a dynamic tool registry to untrusted input. Define explicit allow-lists per agent role. In CrewAI:
researcher = Agent(
role='Researcher',
tools=[exa_search, exa_get_contents], # explicit, minimal
allow_delegation=False # prevent lateral tool escalation
)
The Strands Agents SDK follows the same pattern — tools declared in tools=[] at construction time, not dynamically resolved. Locking this at initialization significantly reduces injection blast radius.
Observability as a security control. Mozilla's pipeline deduplicates and prioritizes findings before human review — the same architecture works for anomaly detection. Amazon Bedrock AgentCore Observability instruments every tool call and LLM invocation as OpenTelemetry spans. Treat unexplained tool call sequences as security events, not just debugging artifacts.
Real-World Use Cases
Mozilla's Claude Mythos pipeline is the clearest production example: an agent that writes its own verification tests before reporting a vulnerability. The self-verification step matters for security hardening too — an agent that confirms its own tool calls against expected behavior before executing them can catch injection attempts that slip past input sanitization.
- For teams adopting SageOX-style context infrastructure, where agents are primed with recorded meeting discussions and organizational memory, the attack surface extends to the memory layer itself. Treat ingested audio transcripts and Slack exports as untrusted input. Apply the same sanitization pipeline you'd apply to external web content.
Limitations and Gotchas
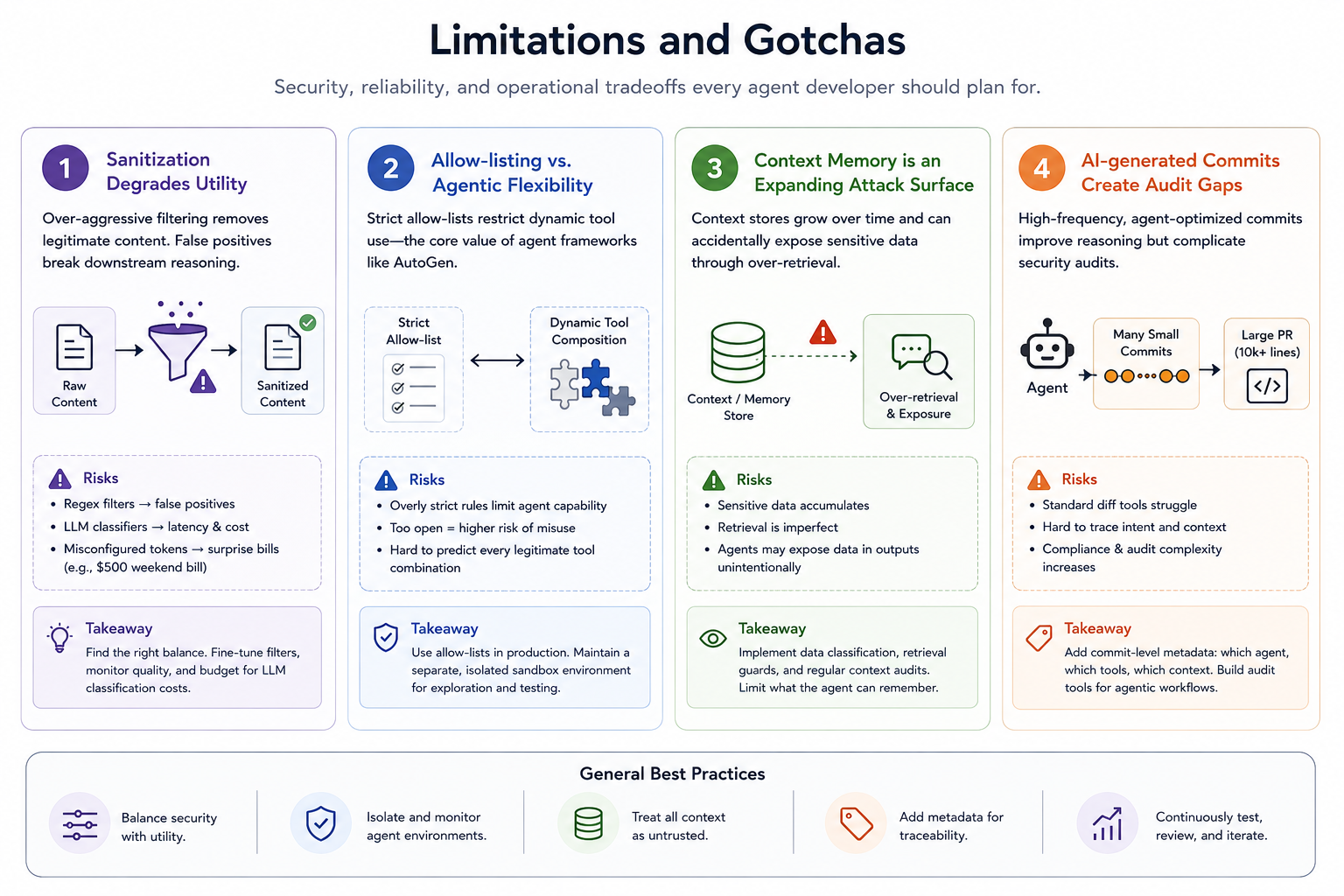
Sanitization degrades agent utility. Over-aggressive filtering strips legitimate content. Regex-based approaches generate false positives that break downstream reasoning. LLM-based classifiers add latency and cost — Arm's SVP of AI notes that misconfigured token consumption produced a $500 weekend bill during development. Budget for it.
Allow-listing fights against agentic flexibility. The value of frameworks like AutoGen is dynamic tool composition. Strict allow-lists constrain that. The honest tradeoff: use allow-lists in production with a separate, isolated sandbox environment for exploratory agent runs.
Context memory is an expanding attack surface. SageOX's "Open Work" model — where internal prompts and planning sessions are public — is an interesting transparency experiment, but in most enterprise deployments, the opposite problem applies: context stores accumulate sensitive data that agents inadvertently expose through over-retrieval.
AI-generated commits create audit gaps. SageOX's CTO advocates for small, high-frequency commits optimized for agent readability. This is good for agent reasoning but complicates security audits. Standard diff review tools aren't designed for 10,000-line agentic PRs. Invest in commit-level metadata tagging: which agent generated this, with which tools, from which context.
What This Means for Your Stack
The Exa + Strands integration is a clean example of what a minimal-trust tool boundary looks like in practice — two explicitly declared tools, structured outputs, no dynamic resolution. That's the model to follow. LangChain's tool ecosystem is more flexible but requires more discipline; AutoGen's multi-agent delegation creates lateral movement risk if agent-to-agent trust isn't scoped.
Arm's perspective — that LLMs are compilers processing natural language into tool calls — is useful framing here. Compilers have well-understood security properties. Your agent's tool execution layer needs the same: input validation, output verification, and explicit trust boundaries between components. Mozilla proved agents can find 20-year-old bugs autonomously. The same pipeline, untrusted, could introduce them. Design accordingly.
Review Mozilla's agentic security pipeline writeup and the Exa best practices documentation before your next production deployment.
