Introduction
With open-weight models like Gemma 4, Qwen3, and Trinity-Large-Thinking now downloadable and fully customizable, developers face a decision that used to belong only to well-funded AI teams: how do you actually adapt a foundation model to your specific problem?
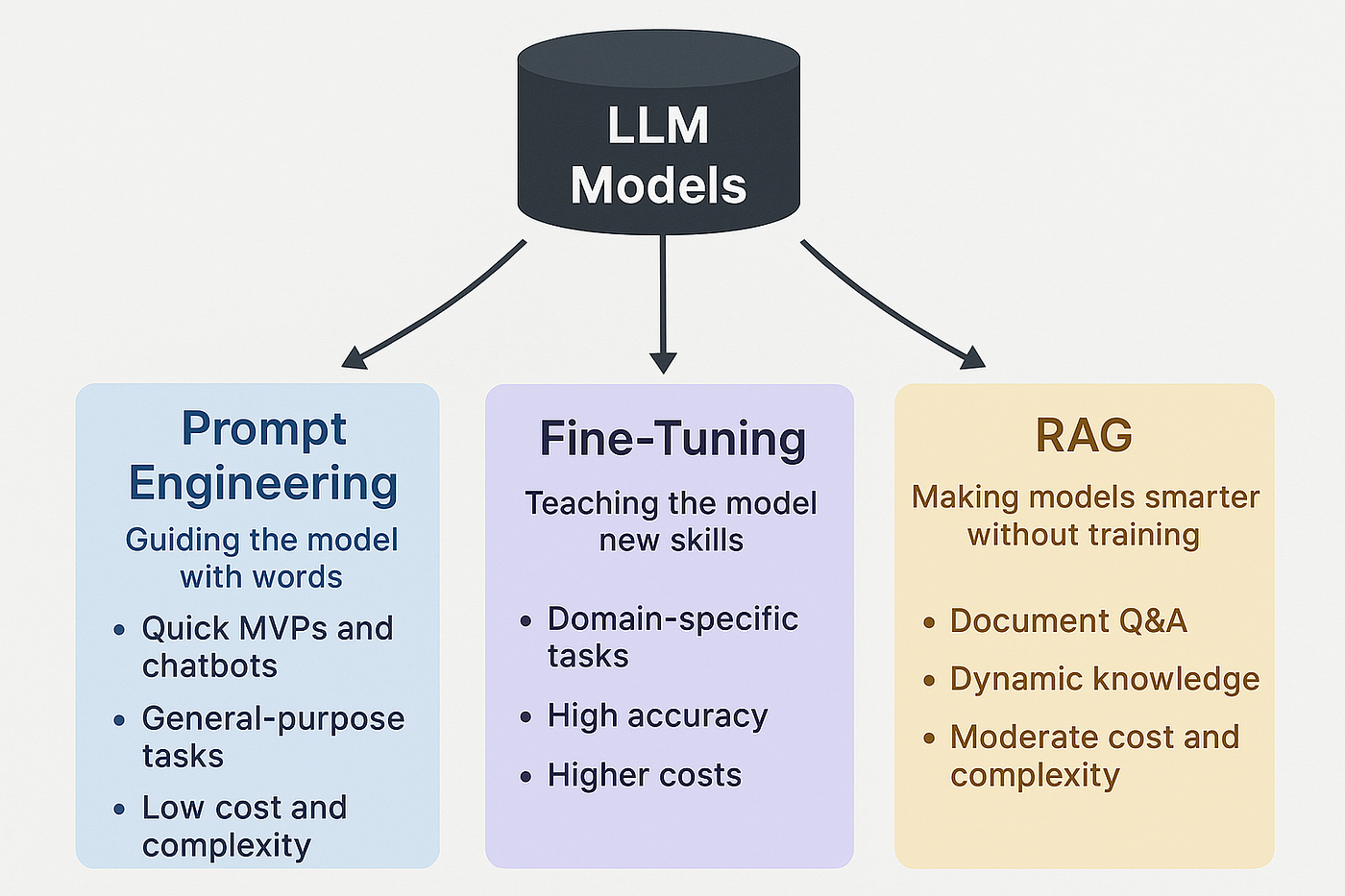
Three strategies dominate the conversation — prompt engineering, retrieval-augmented generation (RAG), and fine-tuning — and the wrong choice costs you time, money, and often model quality. The frustrating reality is that the AI community oversells all three depending on who's talking.
This guide gives you a clear mental model and a practical decision tree so you stop cargo-culting and start choosing deliberately.
The Three Strategies, Honestly Assessed
Prompt Engineering
Prompt engineering means shaping model behavior entirely through the input: system prompts, few-shot examples, chain-of-thought instructions, structured output directives.
When it wins: Your task is well-defined, the base model already has the relevant knowledge, and you need to ship fast. A well-crafted system prompt with three to five examples often outperforms a hastily fine-tuned model.
Hard limits: It can't inject factual knowledge the model never saw. It struggles with consistent tone or domain-specific format requirements at scale. Token costs accumulate when your context window is stuffed with instructions on every call.
Cost: Near zero. Iteration is fast. Start here — always.
Retrieval-Augmented Generation (RAG)
RAG keeps the base model frozen and instead pulls relevant documents into the context window at inference time. The model reasons over retrieved content rather than recalled weights.
When it wins: Your use case is knowledge-intensive and that knowledge changes frequently — internal documentation, product catalogs, legal filings, support tickets. RAG keeps answers grounded and auditable; you can trace exactly which source drove which answer.
This differs from fine-tuning because you're not changing what the model knows, you're changing what it sees. Updates require only re-indexing documents, not retraining.
Hard limits: Retrieval quality is a ceiling. Garbage chunking strategies and weak embeddings produce confidently wrong answers. RAG also adds latency and infrastructure complexity — a vector database, an embedding pipeline, a retrieval layer.
Cost: Moderate infrastructure overhead; no GPU training budget required.
Fine-Tuning
Fine-tuning updates the model's actual weights using your data. This changes how the model thinks, not just what it reads. Use LoRA or QLoRA adapters on open-weight models to do this without owning a data center.
When it wins: You need a specific output style or format that prompting can't reliably enforce — structured JSON extraction, a particular voice, a specialized reasoning pattern. It also wins when you need to reduce inference costs: a fine-tuned 7B model can match a prompted 70B model on narrow tasks at a fraction of the cost.
Hard limits: Fine-tuning does not reliably inject new factual knowledge — it bakes in behavior, not truth. It degrades on tasks outside its training distribution. And it requires a curated, high-quality dataset (typically 500–5,000 examples minimum for meaningful gains).
Cost: High upfront. GPU hours, dataset curation, evaluation, and iteration cycles. Ongoing cost if the task domain drifts.
The Decision Tree
Work through these questions in order:
- Does a well-crafted prompt solve 80% of your cases? If yes, ship with prompt engineering and move on.
- Does the task require current, external, or proprietary knowledge the base model doesn't have? If yes, build a RAG pipeline. Add prompt engineering on top to shape output style.
- Does the task require a consistent behavior, format, or reasoning style that prompting reliably fails to produce — and do you have clean labeled data? If yes, fine-tune. Consider whether you need fine-tuning plus RAG (you often do for knowledge-heavy + behavior-specific tasks).
- Are you trying to teach the model facts via fine-tuning? Stop. Use RAG for knowledge. Fine-tune for behavior.
Quick Reference
- Prompt engineering: days to ship, zero infra, limited control
- RAG: weeks to ship, moderate infra, strong for dynamic knowledge
- Fine-tuning: weeks to months, GPU budget required, highest behavioral control
What This Means
- For developers: Start with prompt engineering on every project. Reach for RAG when knowledge is the problem. Reach for fine-tuning when behavior is the problem. Never use fine-tuning to memorize facts.
- For founders: RAG pipelines have meaningful infrastructure costs that compound at scale — factor this into unit economics early. Fine-tuning has high upfront costs but can dramatically reduce per-call inference spend for high-volume, narrow tasks.
- For teams evaluating open-weight models: The availability of Gemma 4, Qwen3, and similar models makes fine-tuning accessible without API vendor lock-in. The decision framework above still applies — downloadability doesn't change when to fine-tune, only how much it costs.
- For everyone: The strategies stack. Production systems often combine all three — a fine-tuned model with a RAG layer guided by a carefully engineered prompt. Treat them as complementary tools, not competing philosophies.
