
The Whale Surfaces Again
Eighteen months ago, DeepSeek's R1 model hit the AI world like a cold wave—a lean, open-weight reasoning model that matched proprietary American giants at a fraction of the training cost. It briefly erased $600 billion from Nvidia's market cap and forced a global rethink about whether raw compute spending was actually the moat everyone assumed it was.
Now DeepSeek is back with V4, and the question isn't whether it matches R1's cultural shock—it almost certainly won't—but whether it does something arguably more important: systematically compress the economics of frontier AI deployment while advancing China's case for a sovereign AI stack independent of Nvidia.
The answer, based on what's been released, is a qualified yes on both counts.
What DeepSeek V4 Actually Is
V4 ships in two flavors. V4-Pro is a mixture-of-experts model with 1.6 trillion total parameters and 49 billion active per token, making it the largest open-weight model ever released—surpassing Moonshot AI's Kimi K2.6 (1.1 trillion) by a wide margin. V4-Flash is the leaner sibling at 284 billion parameters with 13 billion active. Both carry a one-million-token context window and are released under the MIT License, meaning commercial use, modification, and redistribution are all fair game.
That context window is not just a spec-sheet number. DeepSeek's technical report claims V4-Pro requires only 27% of the compute and 10% of the KV cache that V3.2 needed at a million-token context, achieved through a hybrid attention architecture that compresses older tokens rather than holding everything in memory at equal cost. V4-Flash pushes even further—10% of the FLOPs and 7% of the KV cache. These aren't marginal gains; they're architectural rethinks that make long-context inference genuinely affordable at scale.
DeepSeek researcher Deli Chen called it a "labor of love" 484 days after V3—and structurally, the gap is meaningful. V3.1, V3.2, and even R1 were all built on the original V3 design. V4 is the first clean break: new attention mechanisms, a new optimizer (Muon), and a novel training paradigm that first cultivates more than ten specialized expert models in math, code, and agents, then distills them into a unified student model. The result is a system where DeepSeek doesn't just optimize for inference cost but measurably improves base intelligence—MMLU-Pro jumped from 65.5 to 73.5 between V3.2 and V4-Pro, and the FACTS Parametric benchmark more than doubled.
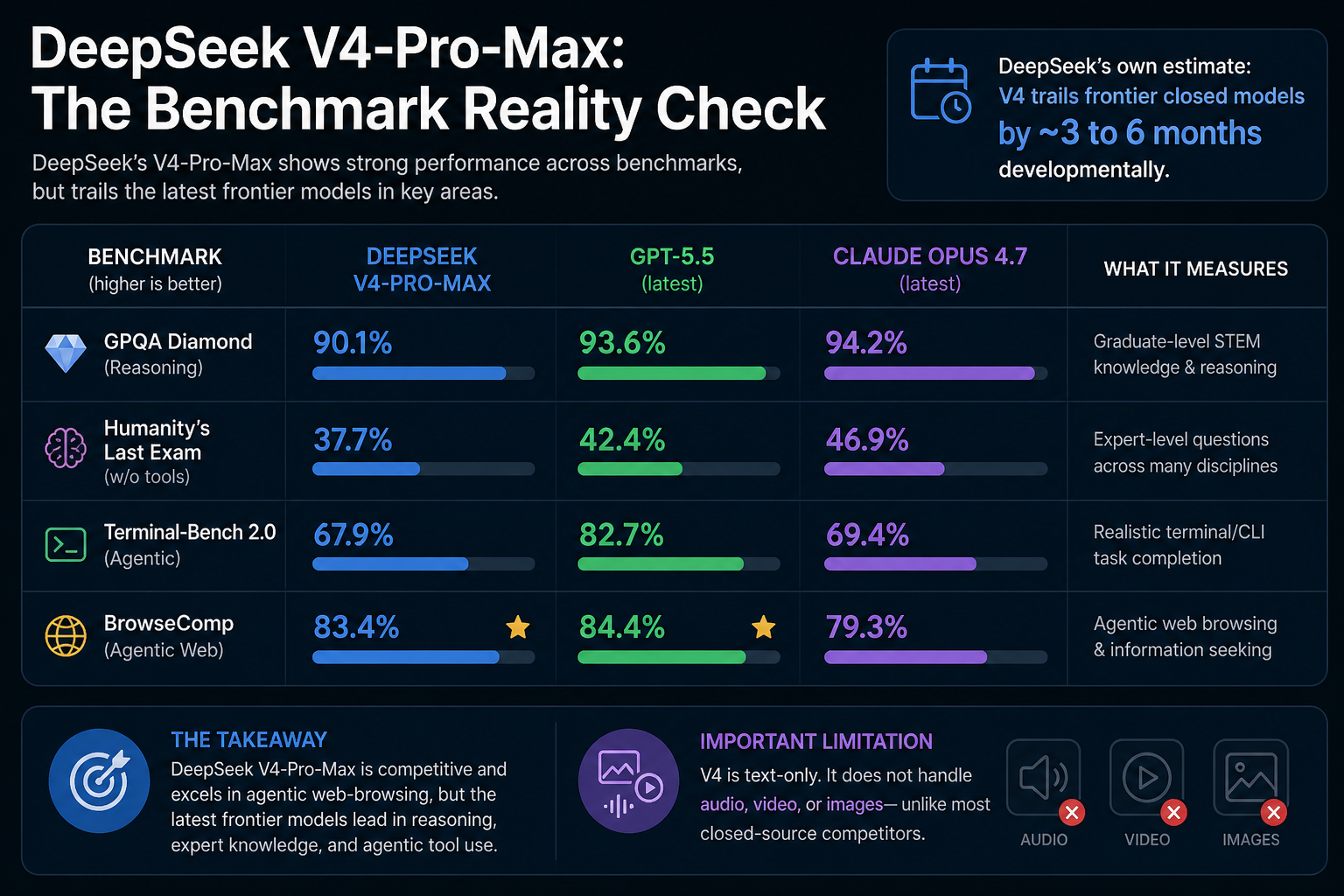
The Benchmark Reality Check
DeepSeek's own comparisons show V4-Pro-Max trading blows with GPT-5.4 and Claude Opus 4.6—but those aren't the newest models anymore. Against GPT-5.5 and Claude Opus 4.7, the picture is more honest and still instructive.
On GPQA Diamond, DeepSeek scores 90.1% versus GPT-5.5 at 93.6% and Claude Opus 4.7 at 94.2%. On Humanity's Last Exam without tools, DeepSeek trails at 37.7% compared to Claude Opus 4.7's 46.9%. Terminal-Bench 2.0 shows a similar story: DeepSeek at 67.9% is competitive with Claude Opus 4.7's 69.4%, but well behind GPT-5.5's 82.7%.
The bright spots are real, though. On BrowseComp—the benchmark measuring agentic web-browsing capability—DeepSeek scores 83.4%, beating Claude Opus 4.7's 79.3% and nearly matching GPT-5.5's 84.4%. DeepSeek's own estimate is that V4 trails frontier closed models by roughly three to six months developmentally. That's an honest self-assessment, and it's more useful than the breathless "beats GPT-5" framing that circulated after the initial release.
The text-only limitation matters too. Unlike most closed-source competitors, V4 doesn't handle audio, video, or images—a real gap for multimodal applications.
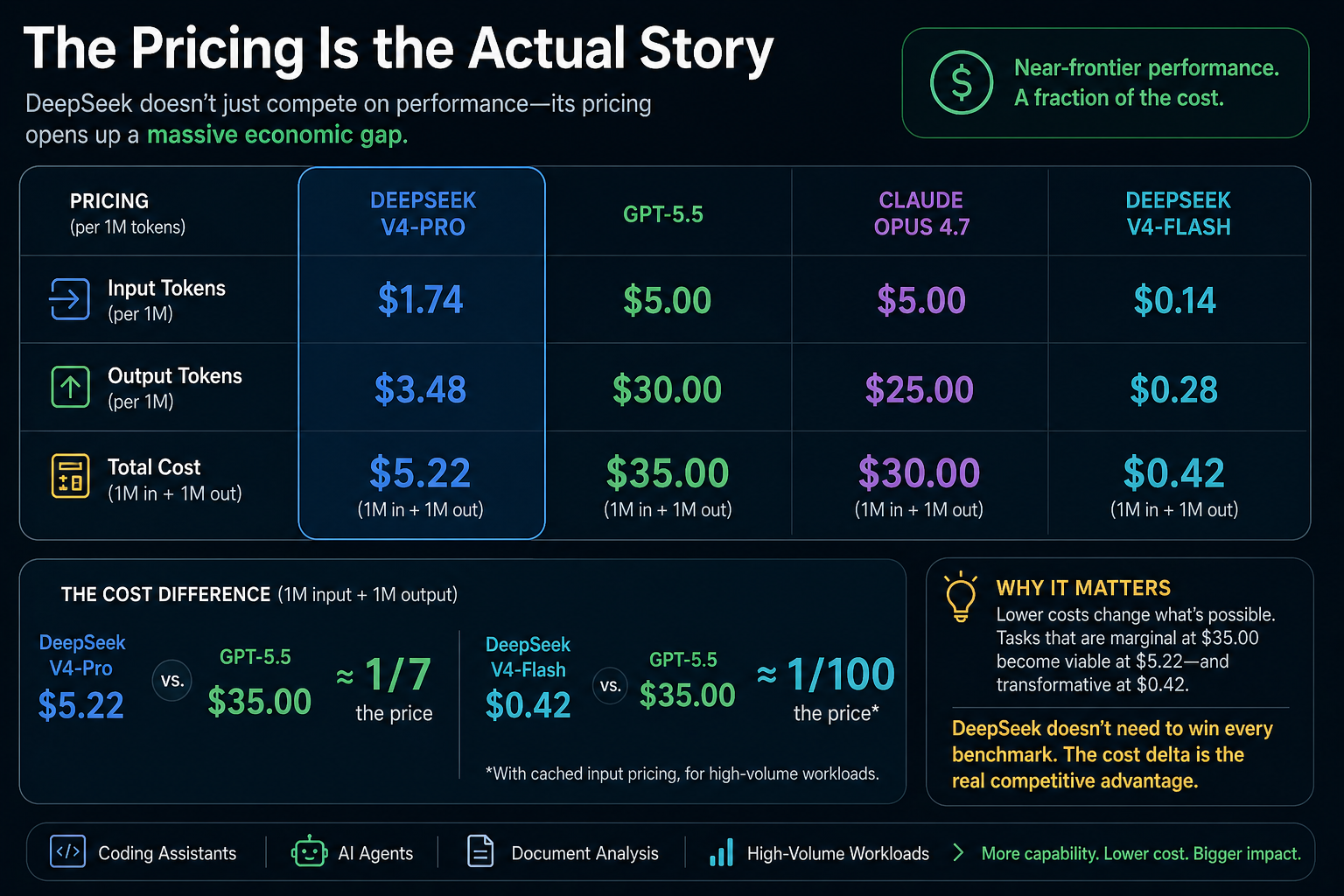
The Pricing Is the Actual Story
Where DeepSeek wins decisively isn't on every leaderboard row—it's in the economic gap it opens between near-frontier performance and what that performance costs.
V4-Pro is priced at $1.74 per million input tokens and $3.48 per million output tokens. GPT-5.5 runs $5.00 input and $30.00 output. Claude Opus 4.7 is $5.00 input and $25.00 output. On a simple million-in, million-out comparison, DeepSeek-V4-Pro costs roughly $5.22 against GPT-5.5's $35.00—about one-seventh the price for performance that trails by single digits on most benchmarks.
V4-Flash is more extreme: $0.14 input and $0.28 output, cheaper than GPT-5.4 Nano. With cached input pricing, it lands at roughly 1/100th the cost of GPT-5.5 for high-volume workloads, with the expected performance tradeoff.
For developers building agents, coding assistants, or document analysis tools, this changes the math on what's worth automating. Tasks that are economically marginal at GPT-5.5 pricing become viable at V4-Pro pricing, and potentially transformative at V4-Flash pricing. DeepSeek doesn't need to win every benchmark to matter—it needs to be close enough on enough tasks that the cost delta can't be ignored.
The Huawei Dimension
This is where V4 becomes geopolitically significant in ways that go beyond AI performance.
DeepSeek's technical report confirms that its expert parallelism scheme has been validated on Huawei Ascend NPUs, delivering a 1.50x to 1.73x speedup over non-Nvidia platforms. Huawei separately confirmed that its Ascend Supernode—built on Ascend 950 AI chips—fully supports V4. DeepSeek also says V4-Pro API prices could fall further once Ascend 950 supernodes ship at scale in the second half of 2026.
To be precise about what this means and doesn't mean: DeepSeek appears to be using Huawei chips primarily for inference rather than training, and MIT Technology Review's sources suggest the full training stack may still lean on Nvidia hardware. Replacing Nvidia entirely—especially for training—remains a hard problem, because Nvidia's advantage isn't just silicon; it's the CUDA software ecosystem built over decades. Adapting that for Ascend requires rebuilding tools from scratch and proving stability at scale.
But validating inference on Huawei hardware is a meaningful step. It provides a blueprint for high-performance AI deployment that doesn't depend on Western GPU supply chains—a capability with obvious strategic value for any country facing or anticipating export controls. China has already moved to ban foreign AI chips in state-funded data centres, and DeepSeek's work has been reported to be part of a broader push toward domestic chip validation.
This puts significant pressure on the US export control regime, because V4's open-weight MIT License means anyone can download and run it on whatever hardware they choose. The model itself can't be embargoed.
What This Means
- For developers: V4-Pro offers near-frontier coding and reasoning performance at a price point that fundamentally changes the cost structure of AI-powered applications. If you're building agents or high-volume inference pipelines, you need to run this model or have a clear reason not to.
- For founders: The pricing compression DeepSeek is forcing on the market is structural, not temporary. Any business model built on the assumption that frontier AI access costs $30-35 per million output tokens needs revision. Margins for pure API resellers get tighter with every V4 release.
- For OpenAI and Anthropic: The challenge isn't that V4 beats GPT-5.5 or Opus 4.7—it doesn't, on most shared benchmarks. The challenge is justifying a 6-7x price premium to enterprise buyers who are increasingly comfortable with open-weight models and whose workloads don't require the last few percentage points of benchmark performance.
- For the chip industry: DeepSeek's Huawei Ascend validation is a proof-of-concept for China's domestic AI stack. It's not Nvidia-replacing yet, but each release moves the benchmark of what "good enough" means for Chinese inference hardware. That trajectory matters more than any single release.
- For the open-source ecosystem: The MIT License on a 1.6T parameter model with a million-token context window and competitive coding performance is a genuine gift to the global developer community. Hugging Face's characterization that "the era of cost-effective 1M context length has arrived" is not hype—it's an accurate description of what shifted this week.
The first DeepSeek moment was about proving that compute efficiency could substitute for raw spending. The second is about proving that the gap between open and closed can be compressed toward zero, one architectural innovation at a time. Whether you're bullish or skeptical about Chinese AI broadly, that's a dynamic that reshapes how the entire industry prices intelligence—and that's not going away.
