
What It Is
Anthropic is running a deliberate two-tier model strategy, and developers need to understand the architecture of that decision before choosing where to build.
Claude Opus 4.7 is the flagship publicly available model — shipping across Amazon Bedrock, Google Vertex AI, and Microsoft Foundry, and accessible via the standard API. Claude Mythos Preview, by contrast, is a restricted-access frontier model currently limited to select enterprise partners including JPMorgan Chase, Nvidia, Apple, Google, and Microsoft — with UK financial institutions granted access imminently, per Anthropic's head of UK operations.
This is not a typical product tiering. Anthropic has explicitly acknowledged in the Opus 4.7 system card that the new release does not advance the company's "capability frontier," because Mythos Preview scores higher on every relevant evaluation. Opus 4.7 was also trained with deliberate efforts to reduce certain cybersecurity capabilities relative to Mythos — making it, by design, the safer and less powerful sibling.
Key Capabilities and Benchmarks
Opus 4.7 is not a minor increment. On SWE-bench Pro, it resolves 64.3% of agentic coding tasks versus 53.4% for Opus 4.6. GPQA Diamond (graduate-level reasoning) sits at 94.2%. Visual reasoning on arXiv Reasoning jumped from 84.7% to 91.0% with tools. On GDPVal-AA knowledge work, it holds an Elo of 1753.
Multimodal support is a meaningful upgrade: the model now accepts images up to 2,576 pixels on the longest edge — a 3× resolution increase — enabling denser screenshot analysis and diagram extraction for computer-use agents. Visual acuity benchmark scores from XBOW reportedly jumped from 54.5% to 98.5%.
The model introduces an xhigh effort parameter, sitting between high and max, giving developers finer control over reasoning depth and token spend. A new task budget API (public beta) lets teams set hard token ceilings for autonomous agent runs — a critical cost-control feature for production workloads.
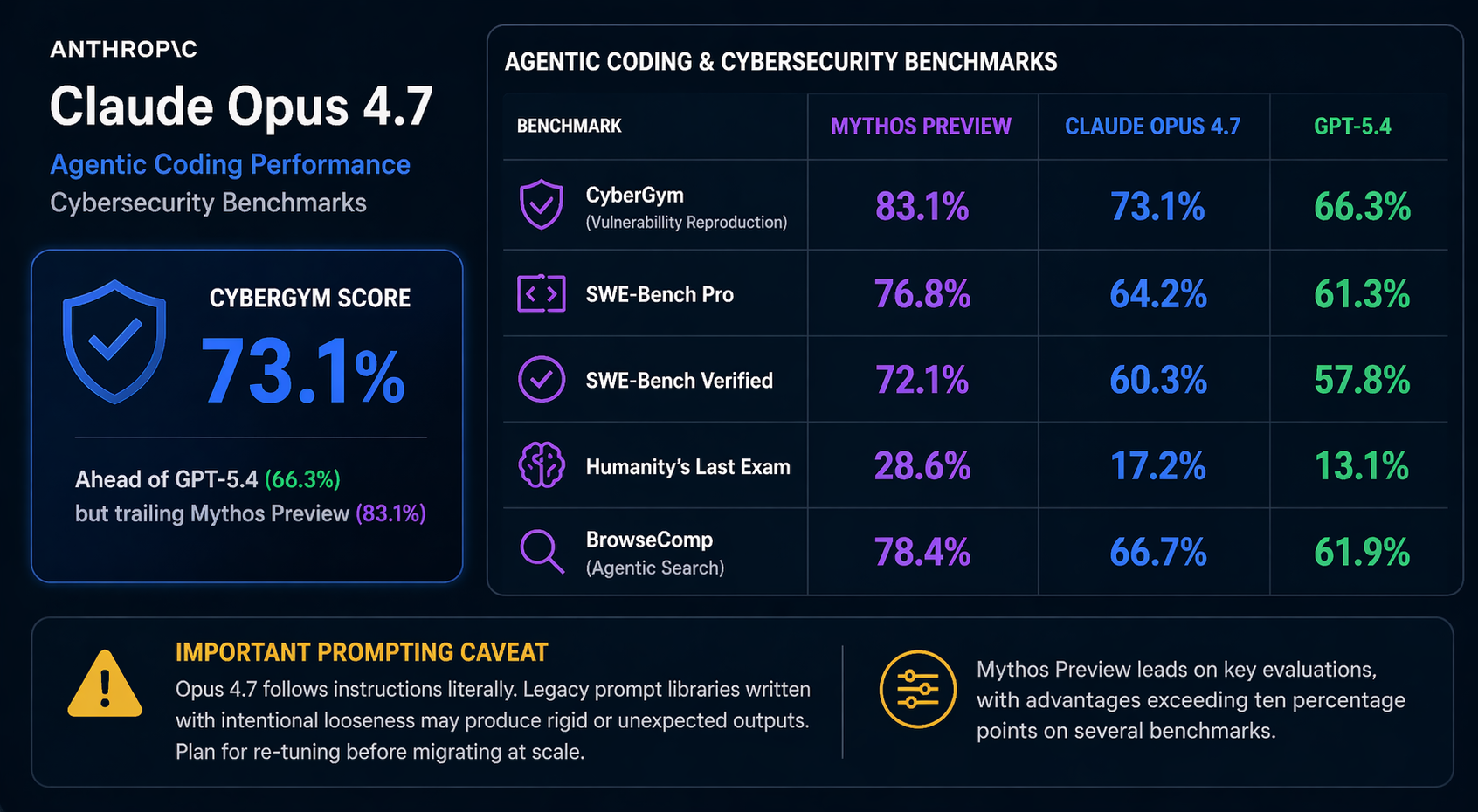
In cybersecurity vulnerability reproduction (CyberGym), Opus 4.7 scores 73.1% — ahead of GPT-5.4's 66.3% but trailing Mythos Preview's 83.1%.
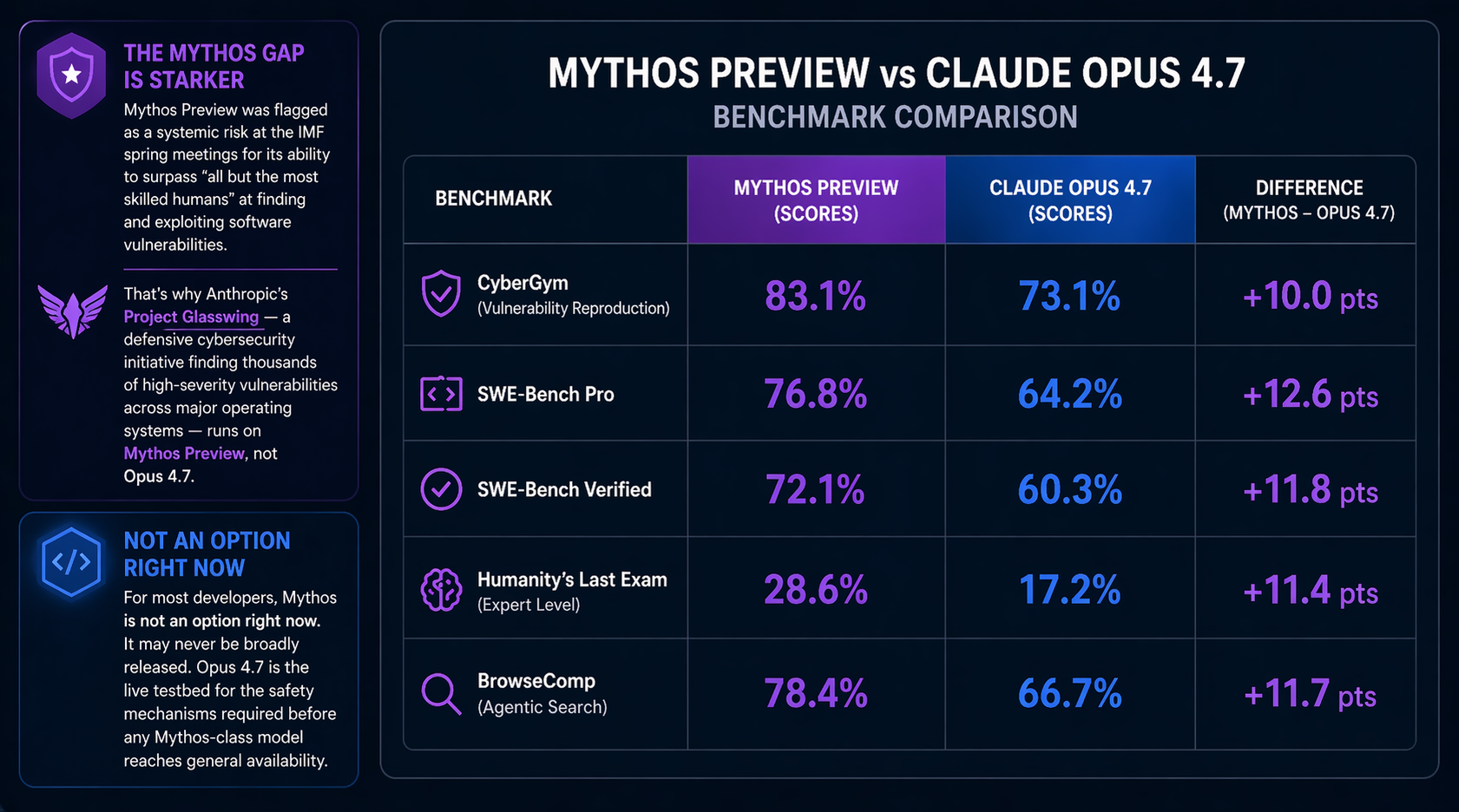
Mythos Preview's benchmark advantages over Opus 4.7 are meaningful: higher scores on SWE-Bench Pro, SWE-Bench Verified, Humanity's Last Exam, and BrowseComp agentic search. The gap exceeds ten percentage points on several of those evaluations.
Important prompting caveat: Opus 4.7 follows instructions literally. Legacy prompt libraries written with intentional looseness may produce rigid or unexpected outputs. Plan for re-tuning before migrating at scale.
How It Compares
Against the immediately competitive field, Opus 4.7 leads GPT-5.4 on GDPVal-AA (1753 vs. 1674 Elo) and on agentic coding and computer-use benchmarks. But the win is not comprehensive: GPT-5.4 leads on agentic search at 89.3% versus Opus 4.7's 79.3%, and holds advantages in multilingual Q&A and raw terminal coding. Gemini 3.1 Pro trails on knowledge work (1314 Elo) but offers a 2M-token context window versus Claude's 1M.
The Mythos gap is starker. Finance ministers and central bank governors at the IMF spring meetings explicitly flagged Mythos as a systemic risk due to its ability to surpass "all but the most skilled humans" at finding and exploiting software vulnerabilities. That capability profile is why Anthropic's Project Glasswing — a defensive cybersecurity initiative already credited with finding thousands of high-severity vulnerabilities across major operating systems — runs on Mythos Preview, not Opus 4.7.
For most developers, Mythos is not an option right now. It may never be broadly released. Anthropic has explicitly framed Opus 4.7 as the live testbed for the safety mechanisms required before any Mythos-class model reaches general availability.
Pricing and API Access
Opus 4.7 pricing is unchanged from 4.6: $5 per million input tokens, $25 per million output tokens. That parity is strategically notable — Anthropic is not charging a premium for what is a substantial capability jump.
One cost risk to model explicitly: the updated tokenizer increases input token counts by 1.0–1.35× on certain inputs, and higher effort levels drive up output token consumption. On paper the rate is identical; in production, your bill may not be.
Mythos Preview has no public pricing or timeline. Access is gated through enterprise partnership, not the standard Claude API. Security professionals wanting expanded cybersecurity access to Opus 4.7 can apply through Anthropic's new Cyber Verification Program.
The redesigned Claude Code desktop app adds "Routines" — cloud-hosted scheduled, API-triggered, and webhook-based automations — with daily limits of 5 (Pro), 15 (Max), and 25 (Team/Enterprise). Parallel agent orchestration remains partially limited in the GUI; the CLI retains flexibility for multi-repo power users.
Bottom Line
Build on Opus 4.7 now. Do not architect for Mythos availability.
Opus 4.7 is the best publicly accessible general-purpose LLM for agentic coding, financial analysis, and long-horizon autonomous workflows as of this writing. Its self-verification loop, literal instruction-following, and effort controls represent genuine production value — not benchmark theater. Enterprise partners including Notion, Replit, and Harvey report concrete workflow improvements.
But approach migration carefully. The tokenizer change plus higher effort token consumption means cost modeling against 4.6 baselines will be wrong. Prompt libraries need review before a full rollout.
Mythos is genuinely more capable — and genuinely restricted. Unless you are a systemically important bank or a named Anthropic enterprise partner, it is not part of your near-term stack. Anthropic is using Opus 4.7 as a staged safety testbed for eventual Mythos access, which means what you deploy today directly informs what gets unlocked later.
- For developers evaluating the tier split: target Opus 4.7 for production agentic systems, and treat the Cyber Verification Program as the credentialed path toward expanded capabilities when they eventually ship.
