
OpenAI has unveiled GPT-5.5, its latest flagship model, and the company isn't being subtle about its ambitions. This isn't just a point-release tune-up — OpenAI is framing it as the foundation for a fundamentally different kind of computing, one where you hand the AI a messy, multi-step problem and walk away. Whether that pitch holds up in practice is the real question.
The model ships with two tiers: a standard GPT-5.5 and a GPT-5.5 Pro variant tuned for high-stakes knowledge work — think legal research, advanced data science, and financial modeling. Both are rolling out to paying ChatGPT subscribers starting Thursday, covering Plus, Pro, Business, and Enterprise tiers. API access is coming "very soon," though OpenAI is citing the need for additional safety infrastructure at scale as the reason for the delay.
The Agentic Pitch: Less Handholding, More Output
The defining feature OpenAI wants you to notice isn't raw benchmark performance — it's what the company calls "agentic" capability. Previous models often required precise, step-by-step prompting to stay on track across long workflows. GPT-5.5 is engineered to absorb a poorly specified, multi-part task and figure out the sequencing itself: researching, writing code, checking its own output, and switching between tools without needing a human to referee each handoff.
Greg Brockman, OpenAI's co-founder and president, framed it bluntly:
What is really special about this model is how much more it can do with less guidance. It can look at an unclear problem and figure out what needs to happen next.
This matters because the biggest bottleneck in AI-assisted work right now isn't intelligence — it's the overhead of managing the AI. If GPT-5.5 genuinely reduces that overhead, it changes the ROI calculation for enterprise deployment significantly.
The efficiency gains are real on paper. OpenAI says GPT-5.5 matches GPT-5.4's per-token latency while completing Codex tasks with meaningfully fewer tokens. In a telling meta-moment, the model itself helped optimize its own serving infrastructure: Codex analyzed OpenAI's production traffic patterns and wrote load-balancing algorithms that boosted token generation speed by over 20%.
Where It Leads, Where It Doesn't
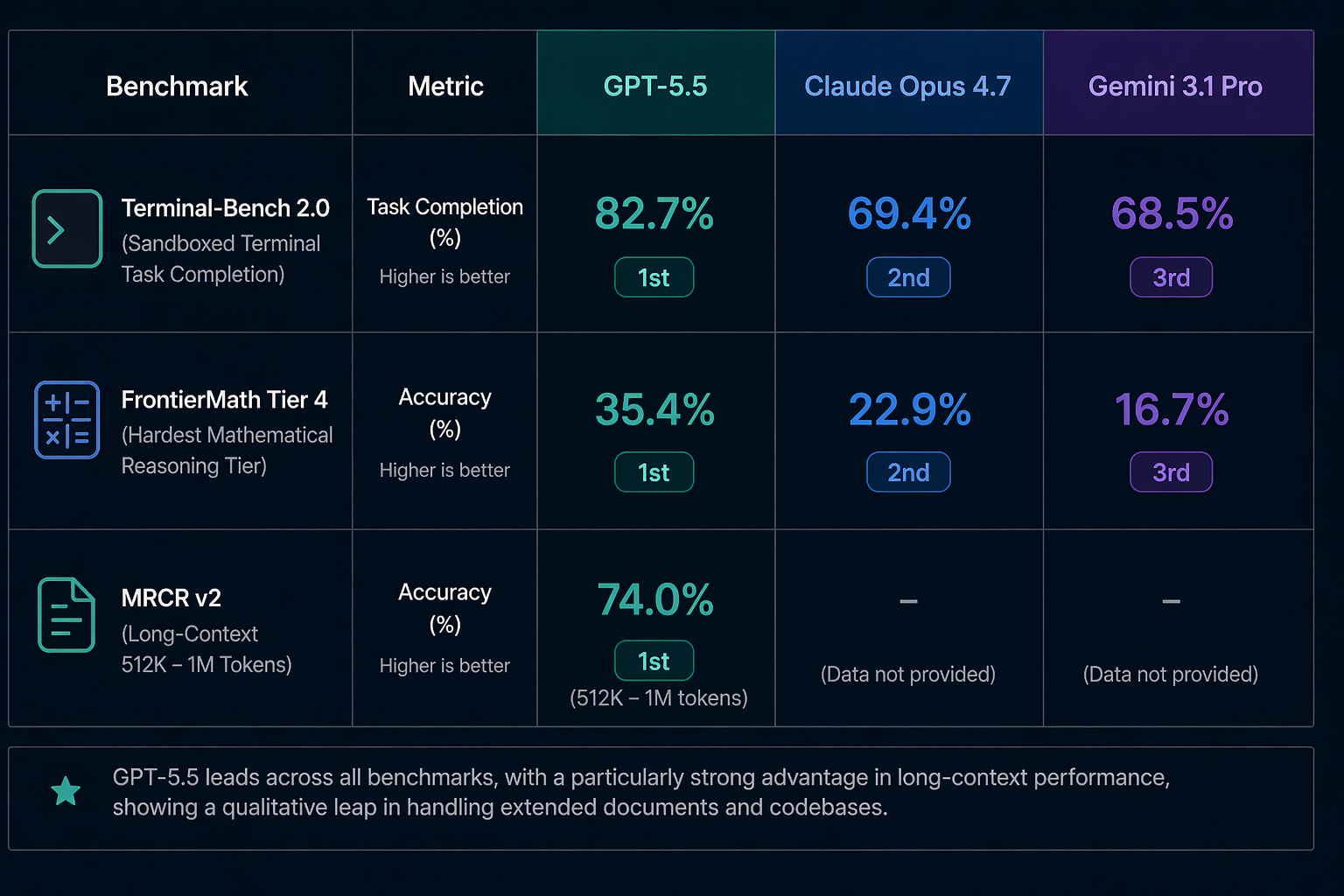
On benchmarks where agentic capability is measured directly, GPT-5.5 is convincingly ahead of the publicly available competition. On Terminal-Bench 2.0, which evaluates sandboxed terminal task completion, GPT-5.5 scores 82.7% — well ahead of Claude Opus 4.7 at 69.4% and Gemini 3.1 Pro at 68.5%. On FrontierMath Tier 4, the hardest mathematical reasoning tier, GPT-5.5 scores 35.4% versus 22.9% for Opus 4.7 and 16.7% for Gemini.
Long-context performance shows perhaps the most dramatic jump. On MRCR v2 at context lengths of 512K to 1 million tokens, GPT-5.5 hits 74.0% — compared to 36.6% for GPT-5.4. That's not iteration; that's a qualitative leap in how the model handles extended documents and codebases.
But the picture isn't uniformly rosy. On SWE-Bench Pro, which tests real-world GitHub issue resolution, Claude Opus 4.7 still outperforms GPT-5.5 by nearly six percentage points. On MCP Atlas, a tool-use benchmark by Scale AI, GPT-5.5 trails both Anthropic and Google. And on Humanity's Last Exam without tools — a pure reasoning gauntlet — GPT-5.5 Pro scores 43.1%, behind Opus 4.7 at 46.9%. The pattern that emerges: OpenAI wins decisively when tools and agency are involved; Anthropic holds ground in zero-shot academic reasoning.
Anthropic's restricted Mythos Preview model, available only to government partners and a small pool of trusted researchers, remains ahead of GPT-5.5 on several benchmarks including SWE-Bench Pro and Humanity's Last Exam. But Mythos isn't a commercial product by design, so for the market that actually matters, OpenAI has reclaimed the top spot.
The Price Hike Developers Can't Ignore
Here's where things get uncomfortable for builders. GPT-5.5's API pricing exactly doubles GPT-5.4's: $5 per million input tokens and $30 per million output tokens, versus $2.50 and $15 previously. GPT-5.5 Pro is stratospheric at $30 input and $180 output per million tokens.
OpenAI's argument is token efficiency — if the model completes the same task in fewer tokens, the effective cost per outcome could be comparable to the previous generation. That's a reasonable argument in theory, and early reports from power users suggest the model does work faster and cleaner. But it's an argument developers will need to verify against their own production workloads before committing.
There's also no GPT-5.5 equivalent of the "mini" or "nano" tiers that existed in the GPT-5.4 era. For developers who built on those lower-cost options, this is a gap that will require either waiting for OpenAI to release smaller variants or rethinking architecture choices entirely.
Safety at Elevated Capability
OpenAI's Preparedness Framework classifies GPT-5.5 as "High" risk across biological and cybersecurity dimensions — the same tier as its recent predecessors, but meaningfully below "Critical." The model shows improved performance on internal security benchmarks, including 88.1% on capture-the-flag tasks versus 83.7% for GPT-5.4, and it's capable enough that OpenAI is rolling out a "Trusted Access for Cyber" program: a specialized license allowing verified security researchers and critical infrastructure defenders to use the model with fewer refusals on security-related prompts.
The company is also delaying API access specifically because security and safety requirements for serving GPT-5.5 at scale differ from what's needed for consumer ChatGPT. That's not just liability management — it reflects a genuine acknowledgment that a model this capable of finding and exploiting vulnerabilities requires a different rollout playbook.
What This Means
- For developers: The capability jump in agentic coding is real and meaningfully ahead of the public competition. But the doubled API pricing and delayed access require careful evaluation. Don't retool production pipelines until you've benchmarked your specific workloads — efficiency gains are task-dependent.
- For founders building on AI: GPT-5.5 accelerates the case for ambient, long-running AI workflows over single-prompt interactions. If your product still centers on single-turn exchanges, the architecture conversation is overdue.
- For Anthropic: This puts direct pressure on a company that just released Opus 4.7 barely a week ago. Losing the publicly available benchmark lead this quickly — even while Mythos remains ahead behind restricted walls — is a PR problem, even if the technical gap is narrow on key metrics.
- For Google: Gemini 3.1 Pro is being outclassed on the benchmarks that enterprise buyers prioritize. The BrowseComp lead is a thin consolation when OpenAI is dominating agentic computer use and complex math.
- For the broader market: OpenAI's chief scientist Jakub Pachocki noted that the company still has "significant headroom" to train smarter models from a scaling perspective. If that's accurate — and there's no particular reason to doubt it — the pace of frontier model releases is going to stay brutal. The real question isn't whether GPT-5.5 is impressive. It clearly is. The question is whether the AI industry's update cadence is outpacing developers' ability to actually build stable products on top of it.
