
What It Is
Open-source automatic speech recognition just crossed a threshold developers have been waiting for. Cohere's Transcribe model — available as cohere-transcribe-03-2026 — is a 2B-parameter encoder-decoder model licensed Apache-2.0, designed explicitly for production deployment rather than research exploration. It targets the gap that has frustrated enterprise voice pipeline builders for years: closed APIs deliver accuracy but impose data residency constraints, while open models have historically traded accuracy for deployability.
Transcribe uses a Conformer encoder paired with a lightweight Transformer decoder. The Conformer architecture is a deliberate choice — convolutional layers handle phoneme-level acoustic detail, while attention layers manage sentence-level context. Standard Transformer-only ASR models tend to be weaker on rapid acoustic transitions; the hybrid design addresses that directly. Training used supervised cross-entropy, a classical but effective objective for minimizing transcript divergence.
For long-form audio — earnings calls, legal recordings, hour-long meetings — the model applies a 35-second chunking strategy with overlapping segments that are reassembled post-inference. This keeps VRAM requirements manageable on consumer-grade GPUs without degrading continuity.
Key Capabilities and Benchmarks
On the Hugging Face Open ASR Leaderboard as of March 26, 2026, Transcribe sits at #1 with an average WER of 5.42% across AMI, Earnings22, GigaSpeech, LibriSpeech (clean/other), SPGISpeech, TED-LIUM, and VoxPopuli. Per-dataset numbers are telling: LibriSpeech clean reaches 1.25% WER, SPGISpeech 3.08%, TED-LIUM 2.49%, and the harder AMI meeting corpus 8.15%. The model supports 14 languages — English, French, German, Italian, Spanish, Portuguese, Greek, Dutch, Polish, Arabic, Vietnamese, Chinese, Japanese, and Korean — with a quality-over-breadth philosophy.
On throughput, Cohere claims 525 minutes of audio processed per real-time minute, which represents a strong real-time factor (RTFx) for the 1B+ parameter class. That combination of low WER and high RTFx is what Cohere means by "extending the Pareto frontier."
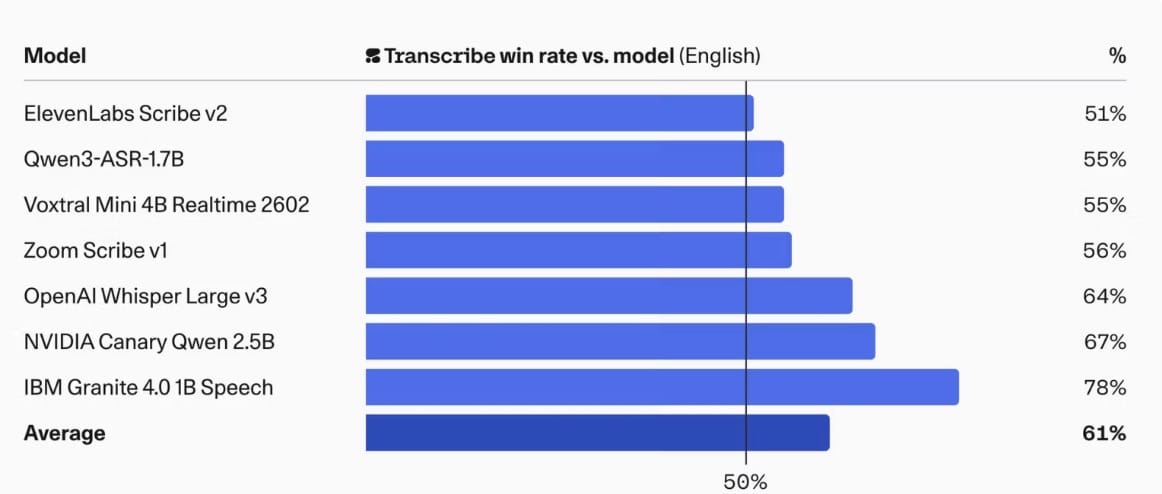
Human preference evaluations in English showed annotators preferred Transcribe outputs 64% of the time over Whisper Large v3, 67% over NVIDIA Canary Qwen 2.5B, 78% over IBM Granite 4.0 1B Speech, and 56% over Zoom Scribe v1 — a meaningful signal beyond raw WER.
Notable constraints: no native speaker diarization, no timestamp output, no automatic language detection, and limited code-switching support. Language must be specified at inference time.
How It Compares
Whisper Large v3 (OpenAI, MIT license): the incumbent open benchmark, posts a 7.44% average WER — nearly 2 full points worse than Transcribe. Whisper was built as a research model and gained commercial use only later; Transcribe ships Apache-2.0 from day one.
ElevenLabs Scribe v2: 5.83% average WER, slightly behind Transcribe. Scribe is a closed API product — no self-hosting path for teams with data residency requirements.
Qwen3-ASR-1.7B: 5.76% average WER, marginally behind, and runs at a smaller parameter count. Worth evaluating for edge deployments where Transcribe's 2B footprint is a constraint.
Mistral Voxtral TTS: not an ASR competitor but relevant context — Mistral is building out a full voice stack with Voxtral, a text-to-speech model based on Ministral 3B, supporting 9 languages with 90ms time-to-first-audio and 6x real-time factor. Mistral's stated roadmap is an end-to-end multimodal pipeline covering audio input and output. If you're planning to build bidirectional voice agents, Mistral's emerging stack is worth tracking alongside Cohere's ASR layer.
Research from the Sommelier paper underscores a broader infrastructure challenge: production full-duplex speech systems require robust multi-speaker data pipelines, and standard ASR models still struggle with diarization errors and hallucinations in overlapping-speech scenarios. Neither Transcribe nor Whisper solves this natively — it remains a pipeline engineering problem.
Pricing and API Access
Cohere is offering Transcribe free via API at launch, accessible through the standard Cohere API endpoint. The model is also available in Model Vault (Cohere's managed inference platform) and via Hugging Face for self-hosted deployment. Apache-2.0 licensing means commercial use, modification, and redistribution are unrestricted — a significant advantage over models with non-commercial or custom licenses. Cohere has signaled plans to integrate Transcribe into its North enterprise agent orchestration platform.
No pricing tiers beyond the free API tier have been publicly announced yet; developers should assume that changes post-launch.
Bottom Line
Cohere Transcribe is the strongest open-weight ASR option available for production pipelines as of mid-2026. Its 5.42% average WER beats Whisper Large v3 by a meaningful margin, matches or edges out closed competitors like ElevenLabs Scribe, and ships with Apache-2.0 licensing that removes friction for enterprise deployment. The Conformer architecture handles acoustic complexity better than pure-Transformer alternatives, and the 35-second chunking logic makes long-form audio practical without specialized infrastructure.
Pick Transcribe if: you need SOTA accuracy, self-hosting control, and commercial licensing. Stick with Whisper if: broad language coverage (99 languages) matters more than peak accuracy. Watch Mistral if you're architecting full-duplex voice agents and want a single-vendor ASR-plus-TTS stack. For teams building on RAG or agent workflows where audio is an input modality, Transcribe closes the open-source accuracy gap that previously forced a tradeoff between performance and data sovereignty.
