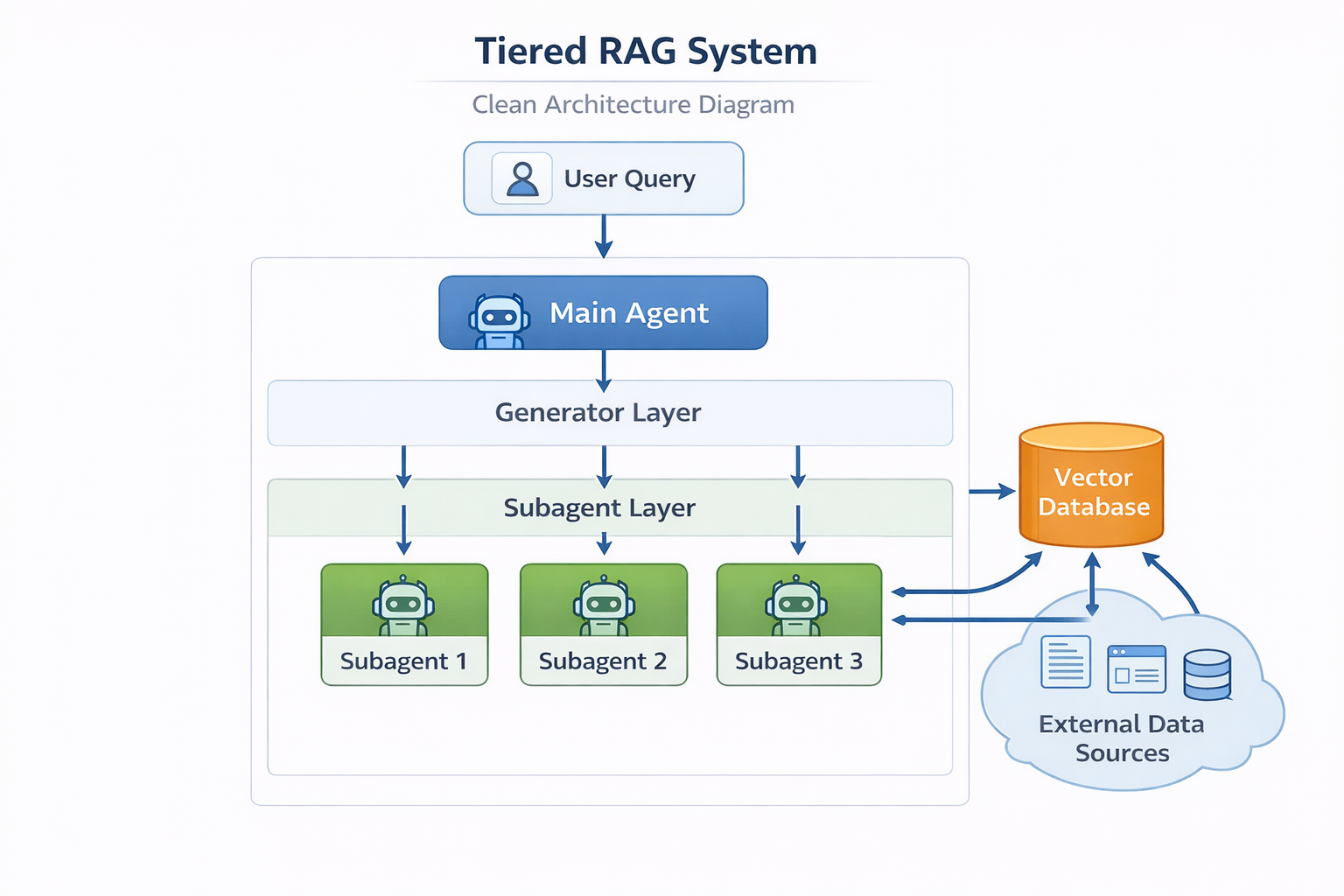
Single-hop RAG is a solved problem. You chunk documents, embed them, retrieve the top-k, and stuff them into a prompt. It works fine when a question has one clear answer hiding in one clear place.
Real-world queries rarely cooperate. "Which of our enterprise customers in the healthcare sector signed contracts after the HIPAA amendment that changed breach notification windows?" That question requires bridging at least three documents, each retrieved conditionally on the last. That's multi-hop retrieval—and most production pipelines fall apart here.
The engineering community is converging on this as the critical unsolved challenge. Chroma's Context-1 release puts numbers on the problem: general-purpose frontier models fail not primarily because of context length, but because of hop-count. As reasoning chains deepen, model accuracy degrades unless the retrieval process is purpose-built for sequential search. Academic work like S-Path-RAG independently confirms this on knowledge graph benchmarks, showing that topology-aware path retrieval beats one-shot text retrieval on multi-hop QA tasks.
This guide gives you a practical architecture and mental model for building pipelines that don't collapse under complexity.

Building a Multi-Hop RAG Pipeline
Step 1: Decompose the Query First
Never send a complex question directly to your vector index. The embedding of a compound question is a blurry average of its parts—you'll retrieve documents loosely relevant to everything and precisely relevant to nothing.
Instead, use an LLM call to decompose the original query into an ordered sequence of atomic subqueries. Each subquery should be answerable with a single retrieval step, and later subqueries should be able to reference answers from earlier ones. This is different from standard query rewriting, which rephrases a single question. Decomposition creates a dependency graph.
A simple prompt pattern: "Break this question into the minimum number of sequential lookup steps needed to answer it. List them in dependency order."
Step 2: Choose Chunking That Preserves Reasoning Bridges
Fixed-size chunking destroys the connective tissue between facts. A 512-token chunk sliced at a sentence boundary may separate the claim from its supporting evidence.
Prefer semantic chunking: split on paragraph and section boundaries, then measure embedding similarity between adjacent chunks. If similarity drops sharply, you have a natural break. If it stays high, merge them. Target chunks that represent a complete thought, not an arbitrary token count.
- For graph-structured knowledge—ontologies, knowledge bases, relational schemas—consider path-based retrieval. S-Path-RAG's core insight is that the shortest semantically weighted path between two entity nodes is often more informative than the nearest embedding neighbors of either node individually. You don't need a full KGQA framework to apply this principle: even maintaining a lightweight entity co-occurrence index alongside your vector store lets you bias retrieval toward documents that bridge query concepts.
Step 3: Retrieve Iteratively, Not in a Single Shot
Execute subqueries sequentially. After each retrieval step, extract the key entity or fact surfaced, then inject it into the next subquery as context. This is "chain-of-retrieval"—each hop is grounded in what the previous hop actually found, not what the original question assumed.
Practically: maintain a running context buffer. After each hop, append retrieved chunks to the buffer and pass the buffer summary (not the full text) as context when formulating the next subquery. This keeps downstream retrievals focused.
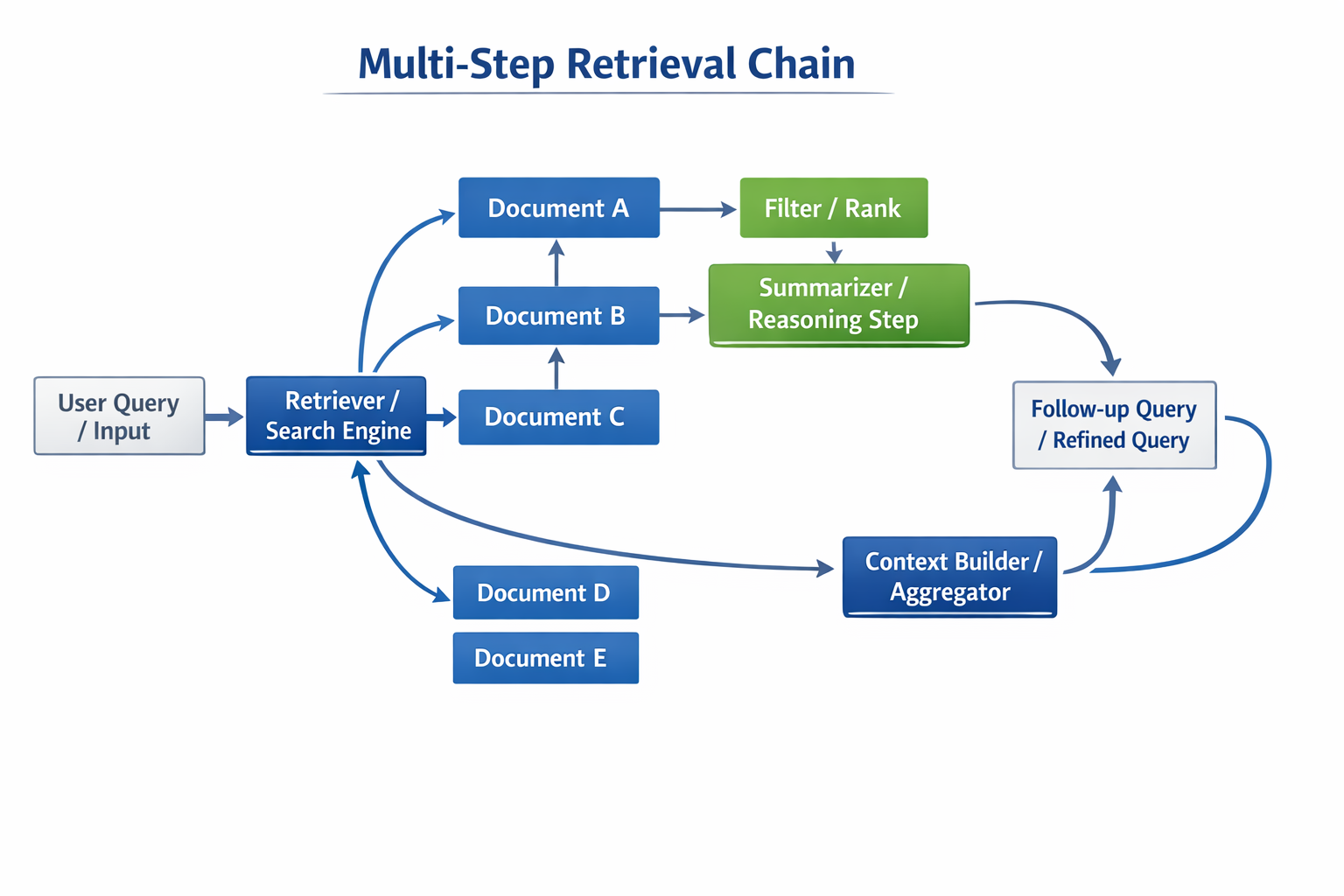
Step 4: Re-rank Aggressively Before Passing to the LLM
Retrieved chunks are candidates, not answers. Run a cross-encoder re-ranker (Cohere Rerank, BGE-reranker, or a fine-tuned model) over the accumulated candidate set after all hops complete. Cross-encoders attend to both the original query and the chunk simultaneously, giving far higher precision than the bi-encoder similarity used during retrieval.
Context-1's architecture makes this explicit by decoupling search from generation entirely—a 20B specialized model acts purely as a retrieval subagent, running hybrid BM25 plus dense search, then pruning its own context mid-search with 0.94 accuracy before handing a curated set to a downstream model. You may not deploy a dedicated 20B scout model, but the principle scales down: never pass raw retrieval output to your generation model. Always filter.
Step 5: Prune Context Before Generation
The "lost in the middle" failure mode is real and well-documented. Frontier models reliably recall information at the start and end of a context window; facts buried in the middle are frequently ignored.
After re-ranking, apply a hard token budget. Keep only chunks that passed re-ranking above a relevance threshold and trim to the top N by score. If your generation model has a 32k window, budget 60% for retrieved context, 20% for conversation history, and 20% for chain-of-thought generation. Resist the temptation to fill the window.
Step 6: Build a Synthetic Evaluation Set
You cannot tune what you cannot measure. Static benchmarks like HotpotQA are useful for sanity checking but tell you nothing about your specific domain.
Generate synthetic multi-hop evaluation tasks using your own documents. The pattern from Chroma's open-sourced data generation tool is instructive: Explore → Verify → Distract → Index. Create questions whose answers require bridging two or more documents, verify the answer chain is grounded, then mine "topical distractors"—documents that look relevant but don't contribute to the answer. This ensures your evaluation tests reasoning under noise, not keyword matching.
Track precision at each hop, not just final answer accuracy. A pipeline that gets the right answer via the wrong path is fragile.
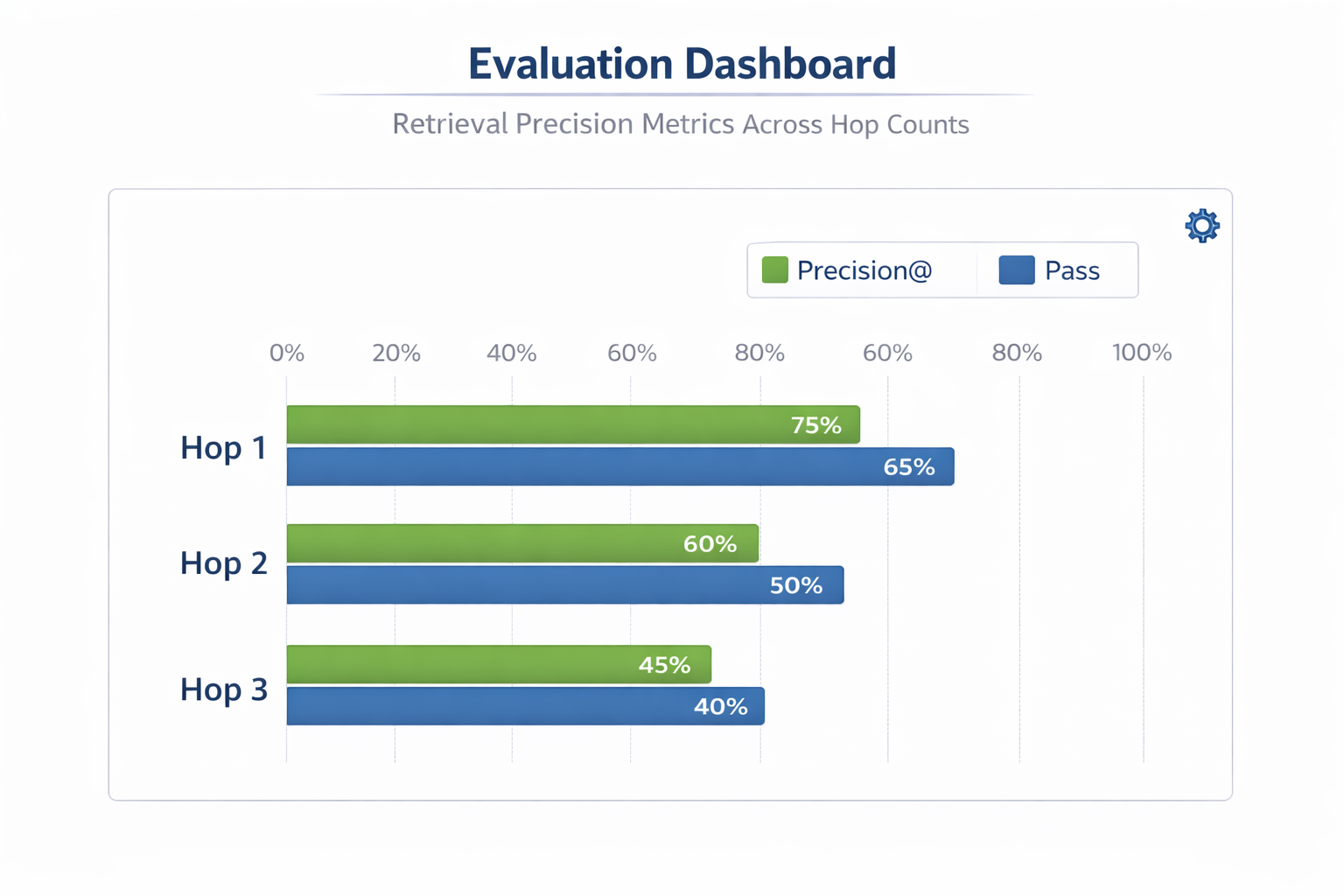
What This Means
The maturation of multi-hop RAG shifts the bottleneck from raw model capability to retrieval architecture. A well-designed 20B specialized retriever can match frontier models on complex search tasks at 10x the speed and 25x lower cost. The engineering investment is in the pipeline, not the model size.
- For developers: Implement query decomposition and iterative retrieval before reaching for a larger model or longer context window. It will solve most failures first.
- For founders: A tiered architecture—fast retrieval subagent plus reasoning frontier model—is more cost-defensible than frontier-only inference at scale.
- For architects: Invest in synthetic evaluation data generation early. You need domain-specific multi-hop benchmarks to know if your pipeline is actually improving between iterations.
- For teams on tight budgets: The "4x parallel agents with reciprocal rank fusion" pattern from Context-1's benchmarks is directly replicable with open-source models. Run multiple retrieval passes with different query decompositions and merge results.
The broader lesson is architectural humility: context windows will keep growing, but throwing more tokens at the problem is not a retrieval strategy. Precision, hop-aware search, and aggressive pruning remain necessary regardless of window size.