AI agents are no longer a research curiosity. Frameworks are maturing, patterns are solidifying, and the gap between "impressive demo" and "production system" is finally closeable — if you understand the underlying architecture.
The confusion persists because most tutorials treat agents as black boxes. You install a framework, call a function, and something runs. That works until it doesn't, and then you have no mental model for debugging or extending it.
This guide tears open the black box. Using nanobot, a ~4,000-line open-source Python framework from HKUDS, as a reference implementation, we'll map every major subsystem — tool execution, memory, skills, session management, subagents, and scheduling — into a reusable mental model you can apply to any agent stack.
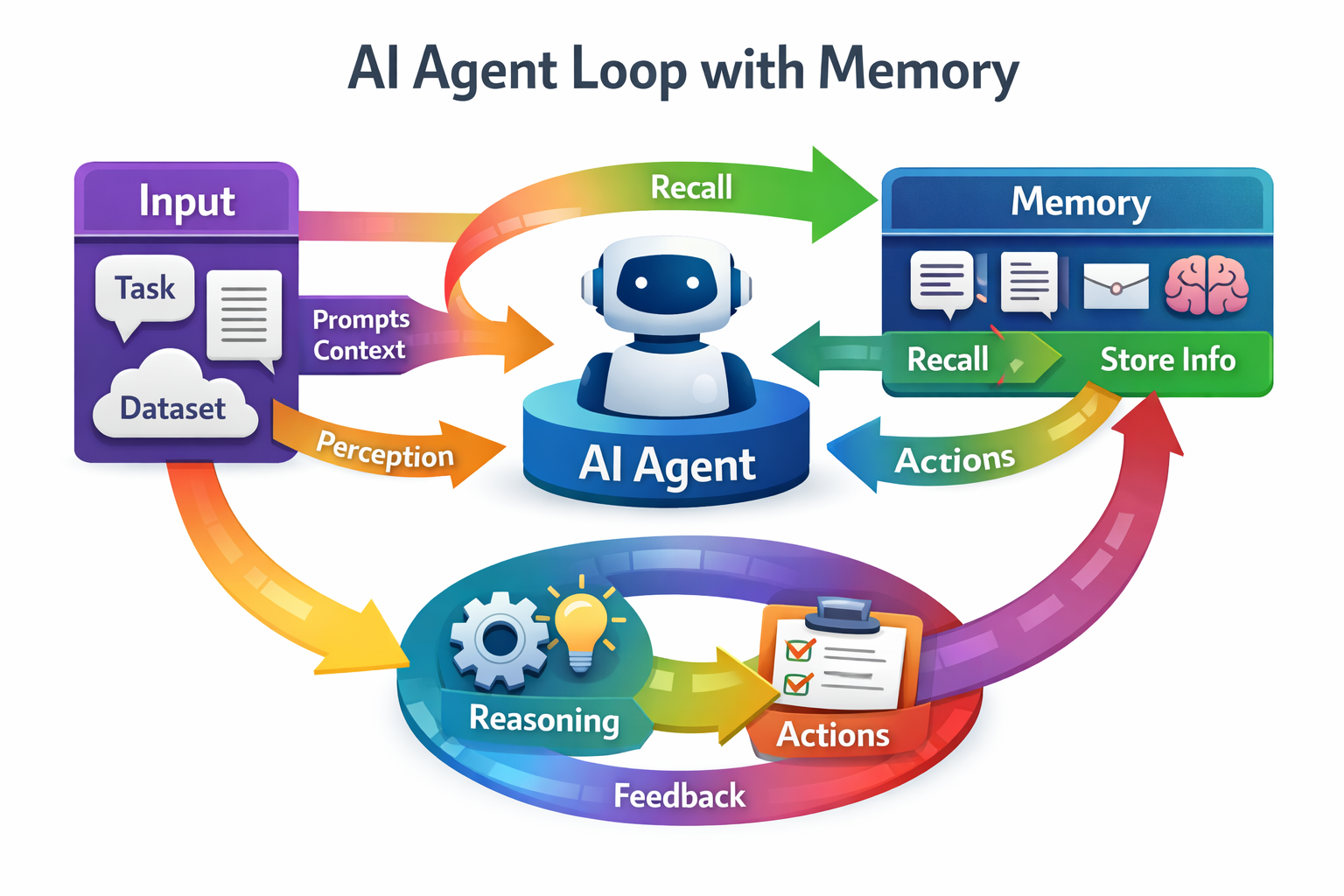
The Core Agent Loop
Every agent framework — LangChain, AutoGen, CrewAI, nanobot — reduces to the same iterative pattern:
- Assemble context: System prompt, loaded memories, skill definitions, conversation history
- Call the LLM: Pass context plus available tool schemas
- Check the response: Did the model request a tool call, or produce a final answer?
- If tool call: Execute the tool, append the result, return to step 2
- If final answer: Return it
That's it. The loop continues until the model stops requesting tools or a maximum iteration count is reached (nanobot defaults to 40). Everything else — memory, skills, subagents — is infrastructure that feeds or extends this core cycle.
This differs from simple chatbots because control flow is dynamic. The LLM decides which tools to invoke and in what order. You're not scripting a workflow; you're giving an LLM a toolkit and a goal.
Tool Use in Practice
Tools are functions with structured schemas. Each tool needs three things: a name, a description the LLM uses to decide when to call it, and a JSON Schema defining its parameters.
{
"name": "write_file",
"description": "Write content to a file in the workspace.",
"parameters": {
"type": "object",
"properties": {
"path": {"type": "string"},
"content": {"type": "string"}
},
"required": ["path", "content"]
}
}
The executor receives the tool name and parsed arguments, runs the function, and returns a string result that gets appended to the conversation. Keep tool descriptions precise — vague descriptions cause the model to misfire.

Memory Architecture: Short vs. Long Term
Memory is where most agent implementations fall short. Two distinct mechanisms serve different purposes.
Short-term memory is just the conversation history in the current context window. It's fast, zero-configuration, and disappears when the session ends. Good for multi-turn tasks within a single run.
Long-term memory requires explicit persistence. The nanobot pattern uses two files: a MEMORY.md that stores consolidated facts (always loaded into context), and daily journal files for recent events (loaded selectively). A periodic consolidation step summarizes old entries to keep context size manageable.
Research from VehicleMemBench, a benchmark for in-vehicle agents with 23 tool modules and 80+ memory events per sample, confirms what practitioners already suspect: powerful models handle direct instructions well, but degrade significantly when preferences evolve over time or conflict across users. Long-term memory isn't solved by just appending facts — it requires active management, deduplication, and consolidation.
Memory Strategy Checklist
- Store facts explicitly, not implicitly — the agent should call a
save_memorytool - Separate volatile context (today's session) from durable facts (MEMORY.md)
- Implement consolidation: summarize old entries periodically to free context space
- Tag memories with timestamps so the agent can reason about recency
- For multi-user systems, namespace memories by user ID
Skills, Subagents, and Scheduling
Skills are markdown files that describe specialized behavioral modes. A code_reviewer.md skill instructs the agent how to evaluate code; a data_analyst.md skill guides statistical reasoning. Skills marked "always available" are loaded into every context; others are injected on demand. This is a lightweight alternative to fine-tuning — you're prompt-engineering at the capability level.
Subagents enable parallelism. The main agent spawns background workers, each with an independent tool registry and its own iteration budget. Critically, subagents should not have access to a spawn tool — this prevents runaway recursive delegation. Results flow back via a message bus. Use subagents for parallel research tasks, not for sequential workflows where ordering matters.
Cron scheduling closes the loop between reactive and proactive behavior. Frameworks like nanobot use APScheduler to trigger agent runs on a schedule — daily briefings, memory consolidation, health checks. The pattern is simple: a scheduled job constructs an inbound message and publishes it to the agent loop, exactly as if a user had sent it. The agent doesn't need to know it was triggered by a clock.

Session Management
A session manager maintains conversation history keyed by a session identifier (e.g., cli:user_123). Each new message loads prior history, passes it into the LLM context, and appends the new turn. Sessions serialize to JSON. Without this layer, every message is stateless — the agent cannot refer to anything said earlier in the same conversation.
What This Means
The patterns above aren't nanobot-specific. They are the architecture of agents, period. Whether you're building on top of a micro-framework or a larger stack, the same decisions recur.
- For developers: Master the core loop first. Add memory, skills, and scheduling incrementally. Instrument every tool call and iteration — observability is the hardest part of debugging agents.
- For founders: Agent reliability scales with the quality of memory management, not model size alone. Invest in consolidation logic early.
- For architects: Subagent parallelism is powerful but operationally expensive. Define clear boundaries between the orchestrator and workers before you need them.
- For the field broadly: As benchmarks like VehicleMemBench demonstrate, dynamic preference modeling remains genuinely unsolved. Long-term adaptive memory is the next frontier, not faster inference.
The right mental model: an agent is a loop, memory is its state, tools are its hands, skills are its operating procedures, and scheduling makes it proactive. Get those five things right and you have a production agent. Get any one wrong and you have an impressive demo.
